Konfiguracja wyszukiwania w sieci
Konfiguracja webSearch pozwala na dostosowanie funkcjonalności wyszukiwania w sieci w ramach LibreChat, w tym dostawców wyszukiwania, skraperów treści oraz mechanizmów zmiany rangi wyników (rerankers).
Przegląd
Funkcja wyszukiwania w sieci składa się z trzech głównych komponentów:
- Dostawcy wyszukiwania: Usługi, które wykonują wstępne wyszukiwanie w sieci
- Scrapers: Usługi, które wyodrębniają zawartość ze stron internetowych
- Rerankers: Usługi, które zmieniają kolejność wyników wyszukiwania w celu uzyskania lepszej trafności
Przykład
webSearch:
# Search Provider Configuration
serperApiKey: "${SERPER_API_KEY}"
searxngInstanceUrl: "${SEARXNG_INSTANCE_URL}"
searxngApiKey: "${SEARXNG_API_KEY}"
searchProvider: "serper" # Options: "serper", "searxng", "tavily"
# Tavily Configuration (search and/or scraper)
tavilyApiKey: "${TAVILY_API_KEY}"
# Optional: custom Tavily-compatible endpoints
tavilySearchUrl: "${TAVILY_SEARCH_URL}"
tavilyExtractUrl: "${TAVILY_EXTRACT_URL}"
# Scraper Configuration
firecrawlApiKey: "${FIRECRAWL_API_KEY}"
firecrawlApiUrl: "${FIRECRAWL_API_URL}"
firecrawlVersion: "${FIRECRAWL_VERSION}"
scraperProvider: "firecrawl" # Options: "firecrawl", "serper", "tavily"
# Reranker Configuration
jinaApiKey: "${JINA_API_KEY}"
jinaApiUrl: "${JINA_API_URL}"
cohereApiKey: "${COHERE_API_KEY}"
rerankerType: "jina" # Options: "jina", "cohere", "none"
# General Settings
scraperTimeout: 7500 # Timeout in milliseconds for scraper requests (default: 7500)
safeSearch: 1 # Options: 0 (OFF), 1 (MODERATE - default), 2 (STRICT)Dostawcy wyszukiwania
searchProvider
| Key | Type | Description | Example |
|---|---|---|---|
| searchProvider | String | Określa, którego dostawcę wyszukiwania użyć. | Options: "serper", "searxng", "tavily" |
serperApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| serperApiKey | String | Nazwa zmiennej środowiskowej dla klucza API Serper. Jeśli nie zostanie ustawiona w .env, użytkownicy zostaną poproszeni o jej podanie przez interfejs użytkownika. | ${SERPER_API_KEY} |
Uwaga: Pobierz swój klucz API z Serper.dev
searxngInstanceUrl
| Key | Type | Description | Example |
|---|---|---|---|
| searxngInstanceUrl | String | Nazwa zmiennej środowiskowej dla adresu URL instancji SearXNG. Jeśli nie zostanie ustawiona w .env, użytkownicy zostaną poproszeni o jej podanie za pośrednictwem interfejsu użytkownika. | ${SEARXNG_INSTANCE_URL} |
searxngApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| searxngApiKey | String | Nazwa zmiennej środowiskowej dla klucza API SearXNG. Jeśli nie zostanie ustawiona w .env, użytkownicy zostaną poproszeni o podanie jej przez interfejs użytkownika. | ${SEARXNG_API_KEY} |
Uwaga: Jest to opcjonalne i wymagane tylko wtedy, gdy Twoja instancja SearXNG wymaga uwierzytelnienia.
tavilyApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyApiKey | String | Nazwa zmiennej środowiskowej dla klucza API Tavily. Używana zarówno do wyszukiwania, jak i scrapowania. Jeśli nie zostanie ustawiona w .env, użytkownicy zostaną poproszeni o jej podanie przez interfejs użytkownika. | ${TAVILY_API_KEY} |
Uwaga: Pobierz swój klucz API z Tavily
tavilySearchUrl
| Key | Type | Description | Example |
|---|---|---|---|
| tavilySearchUrl | String | Nazwa zmiennej środowiskowej dla niestandardowego adresu URL Tavily Search API. Opcjonalna; jeśli nie zostanie ustawiona, domyślnie używane jest wyszukiwanie hostowane przez Tavily. | ${TAVILY_SEARCH_URL} |
tavilyExtractUrl
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyExtractUrl | String | Nazwa zmiennej środowiskowej dla niestandardowego adresu URL API Tavily Extract. Opcjonalne; jeśli nie zostanie ustawione, domyślnie używany jest hostowany ekstraktor Tavily. | ${TAVILY_EXTRACT_URL} |
tavilySearchOptions
| Key | Type | Description | Example |
|---|---|---|---|
| tavilySearchOptions | Object | Opcje konfiguracji wyszukiwania Tavily. |
Podklucze:
| Key | Type | Description | Example |
|---|---|---|---|
| searchDepth | String | Kontroluje kompromis między trafnością a opóźnieniem. "basic" zwraca jedno podsumowanie NLP na adres URL. "advanced" zwraca wiele semantycznie istotnych fragmentów na adres URL (2 kredyty API). "fast" równoważy szybkość i trafność za pomocą fragmentów. "ultra-fast" minimalizuje opóźnienia za pomocą jednego podsumowania NLP. | Options: "basic", "advanced", "fast", "ultra-fast". Default: "basic" |
| maxResults | Number | Maksymalna liczba zwracanych wyników wyszukiwania. | Range: 1-20. Default: 5 |
| topic | String | Kategoria wyszukiwania. "news" jest przydatne do aktualizacji w czasie rzeczywistym. "finance" do danych finansowych. | Options: "general", "news", "finance". Default: "general" |
| includeImages | Boolean | Dołącz obrazy w odpowiedzi. Zwraca zarówno obrazy z zapytania najwyższego poziomu, jak i obrazy dla poszczególnych wyników. | Default: false |
| includeAnswer | Boolean or String | Dołącz odpowiedź wygenerowaną przez LLM. "basic" lub true dla szybkiej odpowiedzi, "advanced" dla szczegółowej odpowiedzi. | Default: false |
| includeRawContent | Boolean or String | Dołącz oczyszczoną i przetworzoną zawartość HTML. "markdown" lub true dla formatu markdown, "text" dla zwykłego tekstu. | Default: false |
| includeDomains | Array of Strings | Ogranicz wyszukiwanie do określonych domen. Maksymalnie 300 domen. | |
| excludeDomains | Array of Strings | Wyklucz określone domeny z wyników. Maksymalnie 150 domen. | |
| timeRange | String | Filtr zakresu czasu oparty na dacie publikacji lub ostatniej aktualizacji. | Options: "day", "week", "month", "year" |
| includeImageDescriptions | Boolean | Gdy includeImages jest ustawione na true, dodaj również opisowy tekst dla każdego obrazu. | Default: false |
| includeFavicon | Boolean | Dołącz adres URL favicon dla każdego wyniku wyszukiwania. | Default: false |
| chunksPerSource | Number | Maksymalna liczba fragmentów istotnej treści na źródło. Dostępne tylko, gdy searchDepth jest ustawione na "advanced". | Range: 1-3. Default: 3 |
| safeSearch | Boolean | Opcjonalne zastąpienie safe_search dla żądań Tavily Search. Domyślnie pominięte; wartość true może wymagać planu Tavily Enterprise. | Default: omitted |
| timeout | Number | Limit czasu żądania HTTP po stronie klienta w milisekundach. Określa, jak długo czekać na odpowiedź API Tavily przed przerwaniem operacji. | Default: 15000 |
Scrapers
firecrawlApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlApiKey | String | Nazwa zmiennej środowiskowej dla klucza API Firecrawl. Jeśli nie zostanie ustawiona w .env, użytkownicy będą proszeni o podanie jej przez UI. | ${FIRECRAWL_API_KEY} |
Uwaga: Pobierz swój klucz API z Firecrawl.dev
firecrawlApiUrl
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlApiUrl | String | Nazwa zmiennej środowiskowej dla adresu URL API Firecrawl. Jeśli nie zostanie ustawiona w .env, użytkownicy zostaną poproszeni o podanie jej przez interfejs użytkownika. | ${FIRECRAWL_API_URL} |
Uwaga: Jest to opcjonalne i wymagane tylko w przypadku korzystania z własnej instancji Firecrawl.
firecrawlVersion
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlVersion | String | Nazwa zmiennej środowiskowej dla wersji API Firecrawl (v0 lub v1). | ${FIRECRAWL_VERSION} |
scraperProvider
| Key | Type | Description | Example |
|---|---|---|---|
| scraperProvider | String | Określa, której usługi scrapera użyć. | Options: "firecrawl", "serper", "tavily" |
firecrawlOptions
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlOptions | Object | Zaawansowane opcje konfiguracji dla scrapera Firecrawl. |
Podklucze:
formats
| Key | Type | Description | Example |
|---|---|---|---|
| formats | Array of Strings | Formaty do uwzględnienia w danych wyjściowych. |
includeTags
| Key | Type | Description | Example |
|---|---|---|---|
| includeTags | Array of Strings | Tagi do uwzględnienia w danych wyjściowych. |
excludeTags
| Key | Type | Description | Example |
|---|---|---|---|
| excludeTags | Array of Strings | Tagi do wykluczenia z danych wyjściowych. |
headers
| Key | Type | Description | Example |
|---|---|---|---|
| headers | Object | Nagłówki do wysłania wraz z żądaniem. Mogą być używane do wysyłania plików cookie, user-agent itp. |
waitFor
| Key | Type | Description | Example |
|---|---|---|---|
| waitFor | Number | Określ opóźnienie w milisekundach przed pobraniem zawartości, aby zapewnić stronie wystarczająco dużo czasu na załadowanie. |
timeout
| Key | Type | Description | Example |
|---|---|---|---|
| timeout | Integer | Limit czasu w milisekundach dla żądania scrapowania. Musi być nieujemną liczbą całkowitą. | Default: 7500 |
maxAge
| Key | Type | Description | Example |
|---|---|---|---|
| maxAge | Number | Zwraca zbuforowaną wersję strony, jeśli jest ona młodsza niż ten czas w milisekundach. Jeśli zbuforowana wersja strony jest starsza niż ta wartość, strona zostanie pobrana ponownie. |
Uwaga: Jeśli nie potrzebujesz bardzo świeżych danych, włączenie tej opcji może przyspieszyć pobieranie danych (scrapes) o 500%.
mobile
| Key | Type | Description | Example |
|---|---|---|---|
| mobile | Boolean | Emuluj scrapowanie z urządzenia mobilnego. |
skipTlsVerification
| Key | Type | Description | Example |
|---|---|---|---|
| skipTlsVerification | Boolean | Pomiń weryfikację certyfikatu TLS podczas wykonywania żądań. |
blockAds
| Key | Type | Description | Example |
|---|---|---|---|
| blockAds | Boolean | Włącza blokowanie reklam oraz wyskakujących okienek z plikami cookie. |
removeBase64Images
| Key | Type | Description | Example |
|---|---|---|---|
| removeBase64Images | Boolean | Usuwa wszystkie obrazy base 64 z danych wyjściowych, które mogą być nadmiernie długie. Tekst alternatywny obrazu pozostaje w danych wyjściowych, ale adres URL zostaje zastąpiony symbolem zastępczym. |
parsePDF
| Key | Type | Description | Example |
|---|---|---|---|
| parsePDF | Boolean | Określa sposób przetwarzania plików PDF podczas scrapowania. |
storeInCache
| Key | Type | Description | Example |
|---|---|---|---|
| storeInCache | Boolean | Jeśli ustawiono na true, strona zostanie zapisana w indeksie i pamięci podręcznej Firecrawl. Ustawienie tej wartości na false jest przydatne, jeśli działania związane ze scrapowaniem mogą budzić obawy dotyczące ochrony danych. Użycie niektórych parametrów związanych z wrażliwym scrapowaniem (nagłówki) wymusi ustawienie tego parametru na false. |
zeroDataRetention
| Key | Type | Description | Example |
|---|---|---|---|
| zeroDataRetention | Boolean | Jeśli ustawiono na true, włączy to zerową retencję danych dla tego scrapowania (wymaga wcześniejszej konfiguracji w Firecrawl). |
location
| Key | Type | Description | Example |
|---|---|---|---|
| location | Object | Lokalizacja geograficzna i ustawienia języka dla scrapingu. |
onlyMainContent
| Key | Type | Description | Example |
|---|---|---|---|
| onlyMainContent | Boolean | Zwracaj tylko główną zawartość strony, z wyłączeniem nagłówków, nawigacji, stopek itp. |
changeTrackingOptions
| Key | Type | Description | Example |
|---|---|---|---|
| changeTrackingOptions | Object | Konfiguracja śledzenia zmian w pobranych treściach. |
Przykład:
webSearch:
firecrawlApiKey: "${FIRECRAWL_API_KEY}"
firecrawlOptions:
formats: ["markdown", "rawHtml"]
includeTags: ["main", "article", ".content"]
excludeTags: ["nav", "footer", ".ads"]
waitFor: 2000
timeout: 10000
mobile: false
blockAds: true
onlyMainContent: true
location:
country: "US"
languages: ["en"]Uwaga: Szczegółowe informacje na temat opcji i ustawień domyślnych narzędzia Firecrawl scraper można znaleźć w dokumentacji API Firecrawl.
tavilyScraperOptions
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyScraperOptions | Object | Opcje konfiguracji dla Tavily Extract (scraper). |
Podklucze:
| Key | Type | Description | Example |
|---|---|---|---|
| extractDepth | String | Głębokość procesu ekstrakcji. "advanced" pobiera więcej danych, w tym tabele i osadzone treści z wyższą skutecznością, ale może zwiększyć opóźnienia. "basic" kosztuje 1 kredyt za każde 5 pomyślnych adresów URL, "advanced" kosztuje 2 kredyty za każde 5 pomyślnych adresów URL. | Options: "basic", "advanced". Default: "basic" |
| includeImages | Boolean | Dołącz listę obrazów wyodrębnionych z adresów URL w odpowiedzi. | Default: false |
| includeFavicon | Boolean | Dołącz adres URL favicon dla każdego wyodrębnionego wyniku. | Default: false |
| format | String | Format wyodrębnionej zawartości strony internetowej. "markdown" zwraca zawartość w formacie markdown. "text" zwraca zwykły tekst i może zwiększyć opóźnienie. | Options: "markdown", "text". Default: "markdown" |
| timeout | Number | Limit czasu w milisekundach. Kontroluje limit czasu HTTP po stronie klienta. Po ustawieniu wysyła również do Tavily limit czasu ekstrakcji po stronie serwera, przeliczony na sekundy i ograniczony do zakresu 1-60 s. | Default: 15000 for basic, 30000 for advanced |
Przykład:
webSearch:
searchProvider: tavily
scraperProvider: tavily
tavilyApiKey: "${TAVILY_API_KEY}"
# Optional: custom Tavily-compatible endpoints
# tavilySearchUrl: "${TAVILY_SEARCH_URL}"
# tavilyExtractUrl: "${TAVILY_EXTRACT_URL}"
tavilySearchOptions:
searchDepth: basic
maxResults: 5
topic: general
tavilyScraperOptions:
extractDepth: basicUwaga: Szczegółowe informacje na temat opcji Tavily API znajdują się w Tavily API Documentation.
Rerankers
jinaApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| jinaApiKey | String | Nazwa zmiennej środowiskowej dla klucza API Jina. Jeśli nie zostanie ustawiona w .env, użytkownicy zostaną poproszeni o jej podanie przez interfejs użytkownika. | ${JINA_API_KEY} |
Uwaga: Pobierz swój klucz API z Jina.ai
jinaApiUrl
| Key | Type | Description | Example |
|---|---|---|---|
| jinaApiUrl | String | Nazwa zmiennej środowiskowej dla adresu URL API Jina. Jeśli nie zostanie ustawiona w .env, użytkownicy zostaną poproszeni o podanie jej przez interfejs użytkownika. | ${JINA_API_URL} |
Uwaga: Jest to opcjonalne i wymagane tylko w przypadku korzystania z własnej instancji Jina.
cohereApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| cohereApiKey | String | Nazwa zmiennej środowiskowej dla klucza API Cohere. Jeśli nie zostanie ustawiona w .env, użytkownicy zostaną poproszeni o podanie jej przez interfejs użytkownika. | ${COHERE_API_KEY} |
Uwaga: Pobierz swój klucz API z Cohere Dashboard
rerankerType
| Key | Type | Description | Example |
|---|---|---|---|
| rerankerType | String | Określa, której usługi rerankera użyć. Ustaw na "none", aby pominąć reranking. | Options: "jina", "cohere", "none" |
Ustawienia ogólne
scraperTimeout
| Key | Type | Description | Example |
|---|---|---|---|
| scraperTimeout | Integer | Limit czasu w milisekundach dla żądań scrapera. Musi być nieujemną liczbą całkowitą. | Default: 7500 |
safeSearch
| Key | Type | Description | Example |
|---|---|---|---|
| safeSearch | Number | Poziom filtrowania bezpiecznego wyszukiwania. 0 = WYŁĄCZONE (brak filtrowania), 1 = UMIARKOWANY (domyślnie), 2 = ŚCISŁY (maksymalne filtrowanie). | Default: 1 (MODERATE) |
Uwaga: Poziomy bezpiecznego wyszukiwania są zgodne ze standardowymi konwencjami API wyszukiwania. Filtrowanie MODERATE jest domyślnie włączone, aby zapewnić rozsądne filtrowanie treści przy jednoczesnym zachowaniu skuteczności wyszukiwania. Tavily domyślnie nie dziedziczy tego globalnego ustawienia; użyj tavilySearchOptions.safeSearch tylko wtedy, gdy Twoje konto Tavily obsługuje safe_search.
Uwagi
- Klucze API można skonfigurować na dwa sposoby:
- Ustaw zmienne środowiskowe określone w konfiguracji YAML
- Jeśli zmienne środowiskowe nie są ustawione, użytkownicy zostaną poproszeni o podanie kluczy API za pośrednictwem interfejsu użytkownika.
- Konfiguracja obsługuje wiele usług dla każdego komponentu (dostawców, scraperów, rerankerów)
- Jeśli określony typ usługi nie zostanie wskazany, system spróbuje użyć wszystkich dostępnych usług w tej kategorii
- Safe search zapewnia trzy poziomy filtrowania treści: OFF (0), MODERATE (1) oraz STRICT (2)
- Tavily domyślnie nie dziedziczy globalnego ustawienia bezpiecznego wyszukiwania; ustaw
tavilySearchOptions.safeSearchjawnie tylko wtedy, gdy Twoje konto Tavily obsługujesafe_search. - Nigdy nie umieszczaj rzeczywistych kluczy API w konfiguracji YAML - używaj wyłącznie nazw zmiennych środowiskowych
Konfiguracja SearXNG
SearXNG to zorientowana na prywatność metawyszukiwarka, którą możesz hostować samodzielnie. Więcej informacji znajdziesz w oficjalnej dokumentacji SearXNG.
Oto kroki, które należy wykonać, aby skonfigurować własną instancję SearXNG do użytku z LibreChat:
Używanie Docker Desktop
-
Wyszukaj oficjalny obraz SearXNG
- Otwórz Docker Desktop
- Wyszukaj
searxng/searxngw zakładce Images. - Kliknij Run przy oficjalnym obrazie, aby automatycznie pobrać i uruchomić kontener z tym obrazem
-
Uruchamianie kontenera
- Rozwiń listę rozwijaną Optional Settings w panelu, który pojawi się po zakończeniu pobierania.
- Ustaw żądane szczegóły konfiguracji (numer portu, nazwę kontenera itp.)
- Kliknij Run, aby uruchomić kontener
-
Konfiguracja SearXNG dla LibreChat
- Przejdź do karty
Filesw Docker Desktop - Przejdź do
/etc/searxng/settings.yaml - Otwórz edytor plików
- Przejdź do sekcji
formats - Dodaj
jsonjako akceptowalny format, aby LibreChat mógł komunikować się z Twoją instancją - Zapisz plik
- Przejdź do karty
-
Zrestartuj kontener
- Zrestartuj kontener, aby zmiany weszły w życie
Przewodnik wideo:
Oto film, który przeprowadzi Cię przez cały proces od początku do końca w około minutę:
Uwaga: W tym przykładzie URL instancji to http://localhost:55011 (numer portu znajduje się pod nazwą kontenera w lewym górnym rogu pod koniec filmu)
Konfiguracja LibreChat do używania SearXNG
Możesz skonfigurować SearXNG w LibreChat z poziomu interfejsu użytkownika lub poprzez librechat.yaml.
Konfiguracja UI
-
Otwórz menu rozwijane narzędzi na pasku wprowadzania czatu
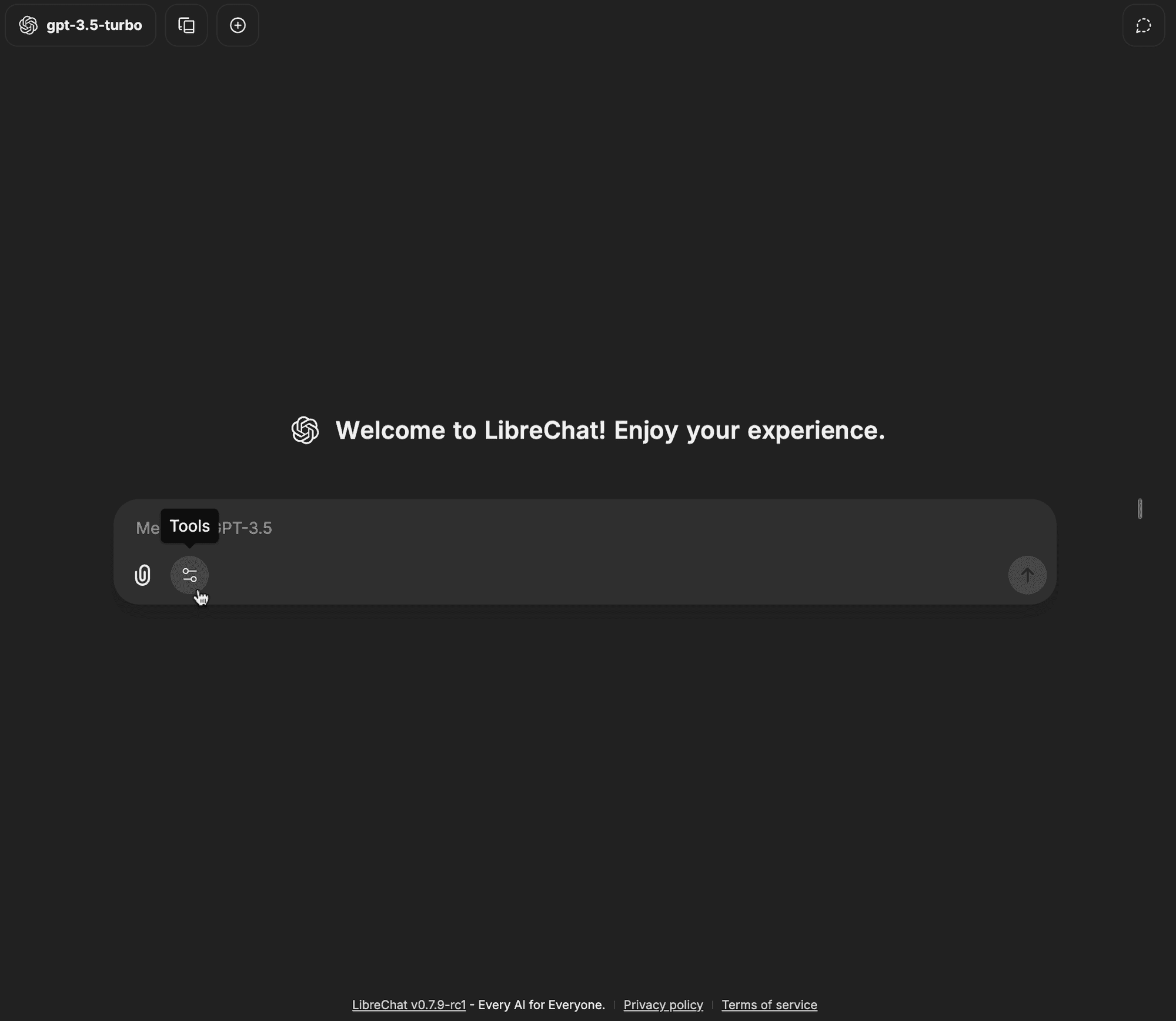
-
Kliknij ikonę koła zębatego obok Web Search
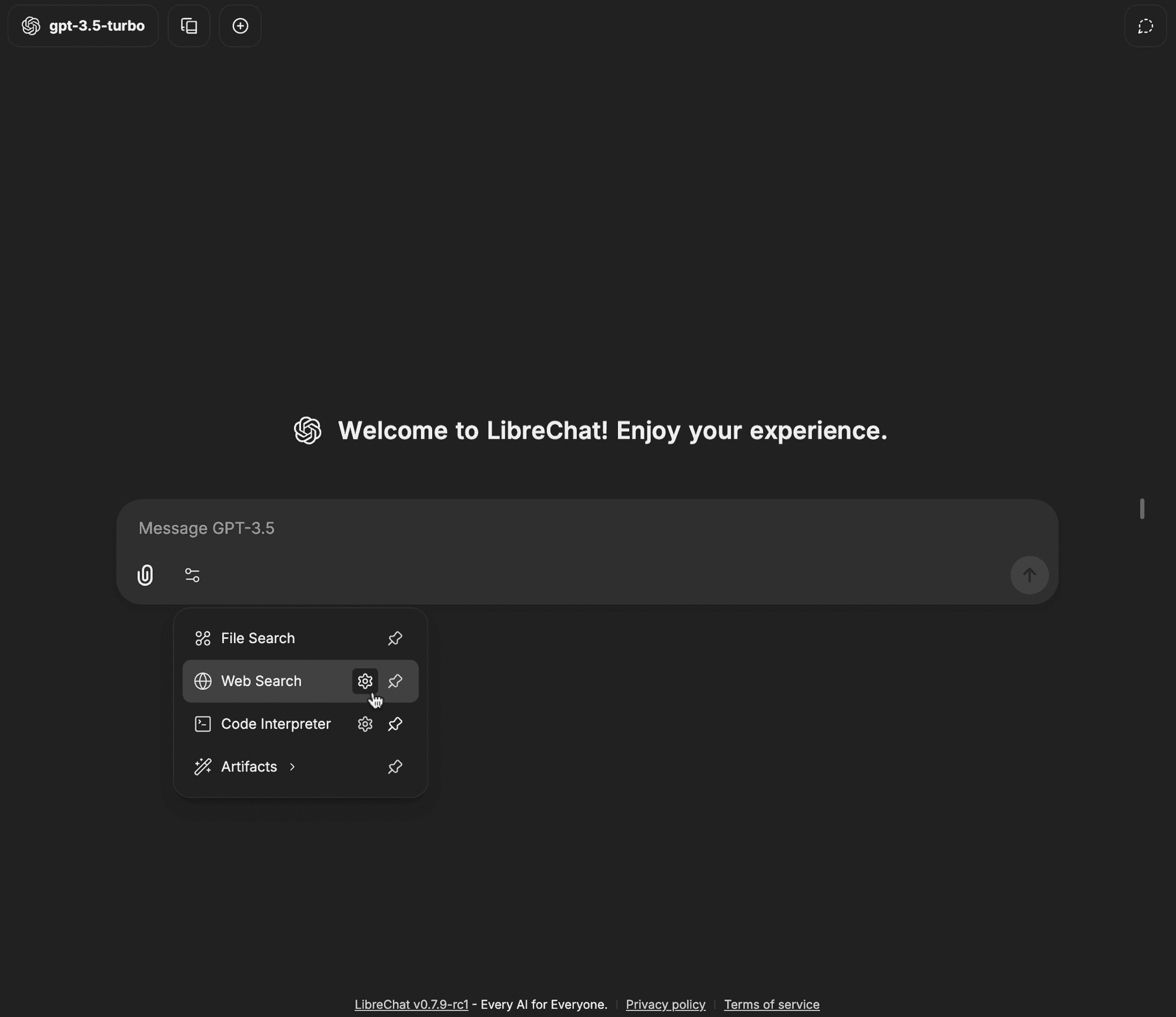
-
Wybierz SearXNG z rozwijanej listy Dostawcy wyszukiwania (Search Provider)
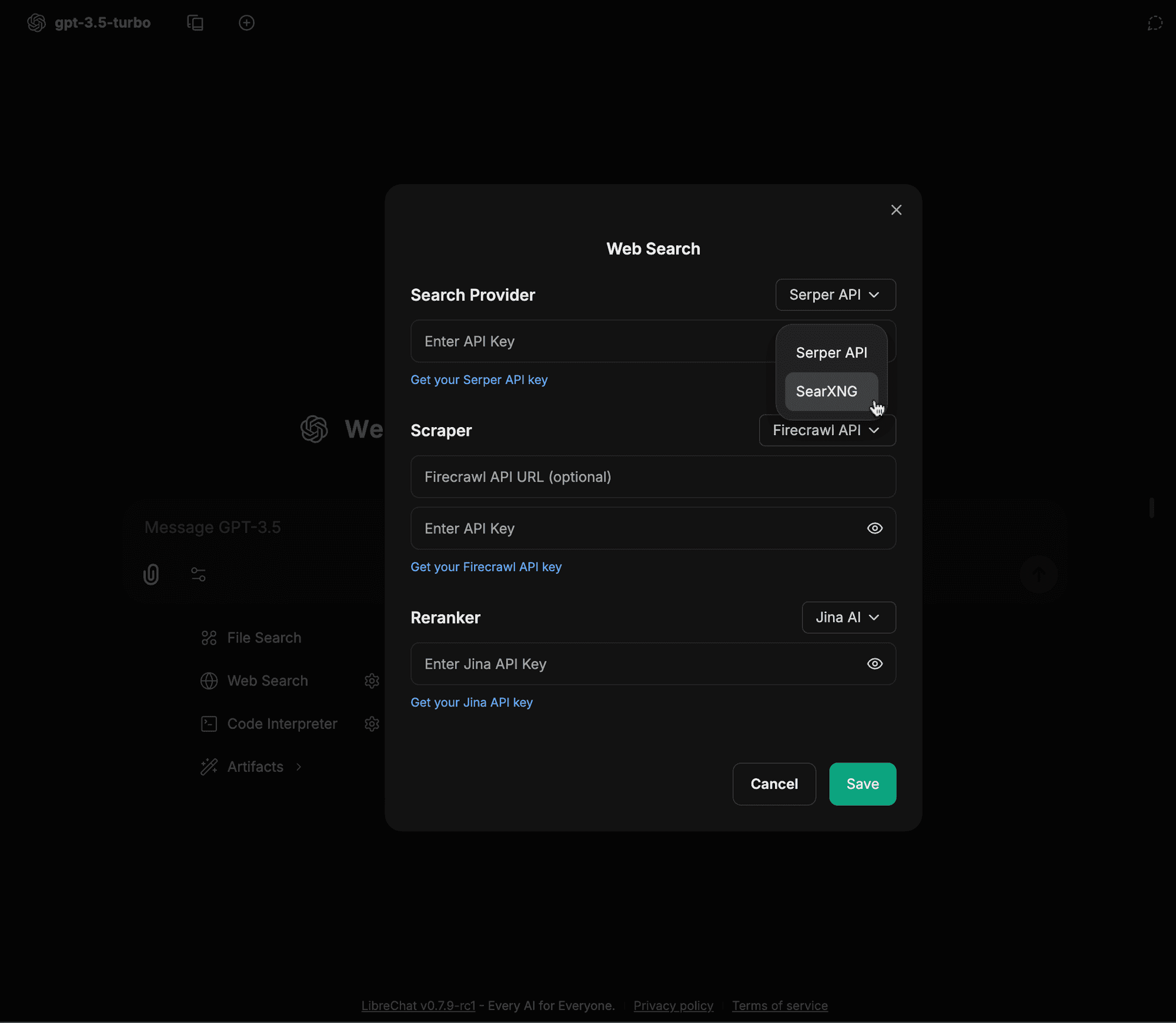
-
Wprowadź szczegóły konfiguracji (np. adres URL instancji, typ scrapera itp.) i kliknij zapisz
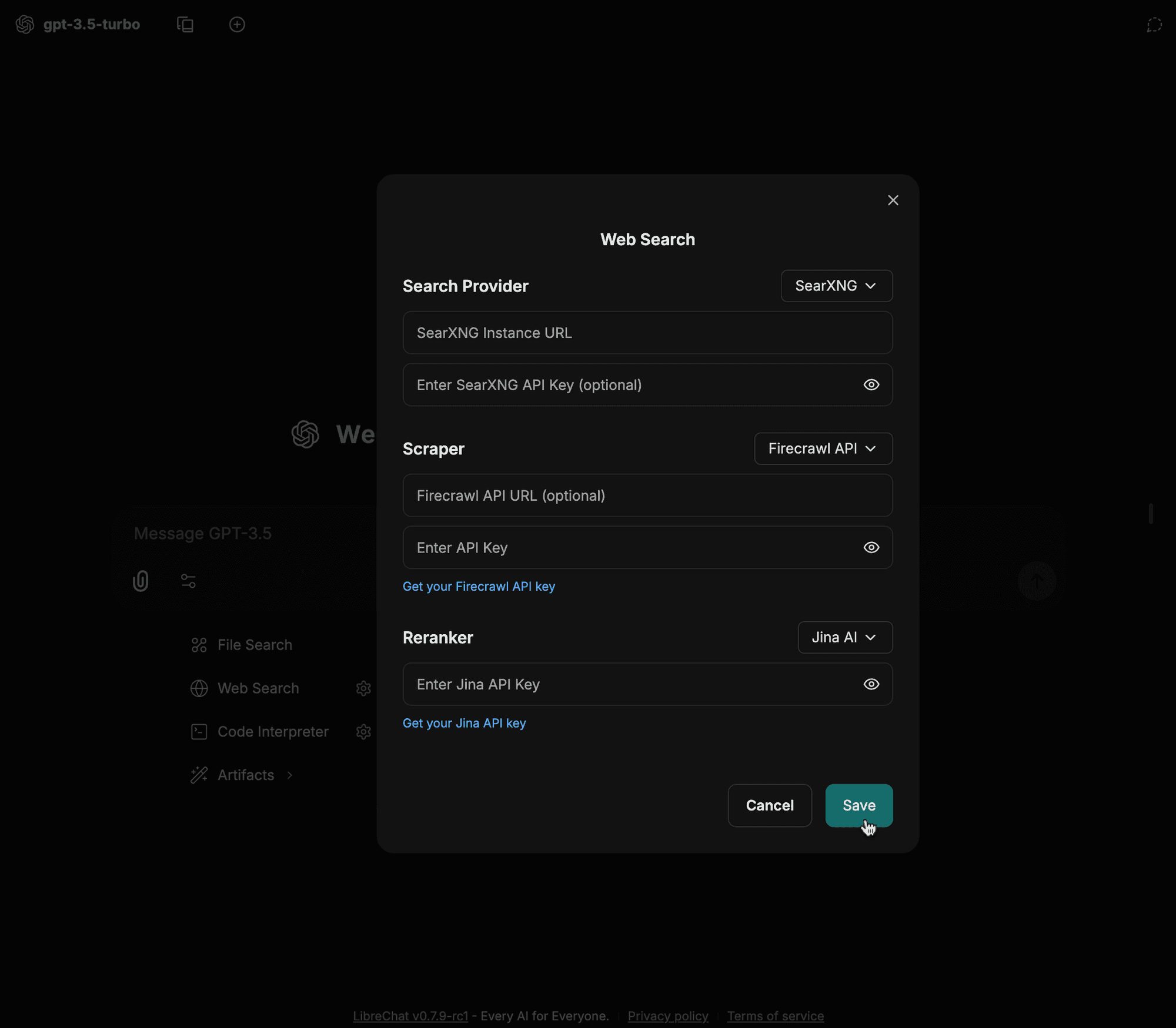
-
Kliknij opcję Web Search w menu rozwijanym narzędzi
-
Odznaka wyszukiwania w sieci (Web Search) powinna być teraz włączona, co oznacza, że Twoje zapytania mogą teraz korzystać z funkcji wyszukiwania w sieci
Jaka jest ta instrukcja?