Configuration de la recherche Web
La configuration webSearch vous permet de personnaliser la fonctionnalité de recherche web au sein de LibreChat, y compris les fournisseurs de recherche, les scrapers de contenu et les rerankers de résultats.
Aperçu
La fonctionnalité de recherche web se compose de trois éléments principaux :
- Fournisseurs de recherche : Services qui effectuent la recherche web initiale
- Scrapers : Services qui extraient du contenu à partir de pages web
- Rerankers : Services qui réordonnent les résultats de recherche pour une meilleure pertinence
Exemple
Fournisseurs de recherche
searchProvider
| Key | Type | Description | Example |
|---|---|---|---|
| searchProvider | String | Spécifie quel fournisseur de recherche utiliser. | Options: "serper", "searxng", "tavily" |
serperApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| serperApiKey | String | Nom de la variable d'environnement pour la clé API Serper. Si elle n'est pas définie dans .env, les utilisateurs seront invités à la fournir via l'interface utilisateur. | ${SERPER_API_KEY} |
Note : Obtenez votre clé API sur Serper.dev
searxngInstanceUrl
| Key | Type | Description | Example |
|---|---|---|---|
| searxngInstanceUrl | String | Nom de la variable d'environnement pour l'URL de l'instance SearXNG. S'il n'est pas défini dans .env, les utilisateurs seront invités à le fournir via l'interface utilisateur. | ${SEARXNG_INSTANCE_URL} |
searxngApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| searxngApiKey | String | Nom de la variable d'environnement pour la clé API SearXNG. Si elle n'est pas définie dans .env, les utilisateurs seront invités à la fournir via l'interface utilisateur. | ${SEARXNG_API_KEY} |
Note : Ceci est facultatif et n'est nécessaire que si votre instance SearXNG nécessite une authentification.
tavilyApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyApiKey | String | Nom de la variable d'environnement pour la clé API Tavily. Utilisée à la fois pour la recherche et le scraper. Si elle n'est pas définie dans .env, les utilisateurs seront invités à la fournir via l'interface utilisateur. | ${TAVILY_API_KEY} |
Remarque : Obtenez votre clé API auprès de Tavily
tavilySearchUrl
| Key | Type | Description | Example |
|---|---|---|---|
| tavilySearchUrl | String | Nom de la variable d'environnement pour une URL d'API Tavily Search personnalisée. Optionnel ; utilise la recherche hébergée par Tavily par défaut si non défini. | ${TAVILY_SEARCH_URL} |
tavilyExtractUrl
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyExtractUrl | String | Nom de la variable d'environnement pour une URL d'API Tavily Extract personnalisée. Optionnel ; utilise l'extracteur hébergé par Tavily par défaut si non défini. | ${TAVILY_EXTRACT_URL} |
tavilySearchOptions
| Key | Type | Description | Example |
|---|---|---|---|
| tavilySearchOptions | Object | Options de configuration pour la recherche Tavily. |
Sous-clés :
| Key | Type | Description | Example |
|---|---|---|---|
| searchDepth | String | Contrôle le compromis entre pertinence et latence. "basic" renvoie un résumé NLP par URL. "advanced" renvoie plusieurs extraits sémantiquement pertinents par URL (2 crédits API). "fast" équilibre vitesse et pertinence avec des extraits. "ultra-fast" minimise la latence avec un seul résumé NLP. | Options: "basic", "advanced", "fast", "ultra-fast". Default: "basic" |
| maxResults | Number | Le nombre maximal de résultats de recherche à retourner. | Range: 1-20. Default: 5 |
| topic | String | La catégorie de la recherche. "news" est utile pour les mises à jour en temps réel. "finance" pour les données financières. | Options: "general", "news", "finance". Default: "general" |
| includeImages | Boolean | Inclure des images dans la réponse. Renvoie à la fois les images de la requête de premier niveau et les images par résultat. | Default: false |
| includeAnswer | Boolean or String | Inclure une réponse générée par LLM. "basic" ou true pour une réponse rapide, "advanced" pour une réponse détaillée. | Default: false |
| includeRawContent | Boolean or String | Inclure le contenu HTML nettoyé et analysé. "markdown" ou true pour le format markdown, "text" pour le texte brut. | Default: false |
| includeDomains | Array of Strings | Restreindre la recherche à des domaines spécifiques. Maximum 300 domaines. | |
| excludeDomains | Array of Strings | Exclure des domaines spécifiques des résultats. Maximum 150 domaines. | |
| timeRange | String | Filtre de plage temporelle basé sur la date de publication ou de dernière mise à jour. | Options: "day", "week", "month", "year" |
| includeImageDescriptions | Boolean | Lorsque includeImages est défini sur true, ajoutez également un texte descriptif pour chaque image. | Default: false |
| includeFavicon | Boolean | Inclure l'URL du favicon pour chaque résultat de recherche. | Default: false |
| chunksPerSource | Number | Nombre maximal de segments de contenu pertinents par source. Uniquement disponible lorsque searchDepth est défini sur "advanced". | Range: 1-3. Default: 3 |
| safeSearch | Boolean | Remplacement optionnel de safe_search pour les requêtes de recherche Tavily. Omis par défaut ; true peut nécessiter Tavily Enterprise. | Default: omitted |
| timeout | Number | Délai d'expiration de la requête HTTP côté client en millisecondes. Contrôle la durée d'attente de la réponse de l'API Tavily avant d'abandonner. | Default: 15000 |
Scrapers
firecrawlApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlApiKey | String | Nom de la variable d'environnement pour la clé API Firecrawl. Si elle n'est pas définie dans .env, les utilisateurs seront invités à la fournir via l'interface utilisateur. | ${FIRECRAWL_API_KEY} |
Remarque : Obtenez votre clé API sur Firecrawl.dev
firecrawlApiUrl
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlApiUrl | String | Nom de la variable d'environnement pour l'URL de l'API Firecrawl. S'il n'est pas défini dans .env, les utilisateurs seront invités à le fournir via l'interface utilisateur. | ${FIRECRAWL_API_URL} |
Note : Ceci est facultatif et n'est nécessaire que si vous utilisez une instance Firecrawl personnalisée.
firecrawlVersion
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlVersion | String | Nom de la variable d'environnement pour la version de l'API Firecrawl (v0 ou v1). | ${FIRECRAWL_VERSION} |
scraperProviderider
| Key | Type | Description | Example |
|---|---|---|---|
| scraperProvider | String | Spécifie quel service de scraping utiliser. | Options: "firecrawl", "serper", "tavily" |
firecrawlOptions
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlOptions | Object | Options de configuration avancées pour le scraper Firecrawl. |
Sous-clés :
formats
| Key | Type | Description | Example |
|---|---|---|---|
| formats | Array of Strings | Formats à inclure dans la sortie. |
includeTags
| Key | Type | Description | Example |
|---|---|---|---|
| includeTags | Array of Strings | Tags à inclure dans la sortie. |
excludeTags
| Key | Type | Description | Example |
|---|---|---|---|
| excludeTags | Array of Strings | Balises à exclure de la sortie. |
headers
| Key | Type | Description | Example |
|---|---|---|---|
| headers | Object | En-têtes à envoyer avec la requête. Peuvent être utilisés pour envoyer des cookies, un user-agent, etc. |
waitFor
| Key | Type | Description | Example |
|---|---|---|---|
| waitFor | Number | Spécifiez un délai en millisecondes avant de récupérer le contenu, permettant à la page suffisamment de temps pour se charger. |
timeout
| Key | Type | Description | Example |
|---|---|---|---|
| timeout | Integer | Délai d'attente en millisecondes pour la requête de scraping. Doit être un entier non négatif. | Default: 7500 |
maxAge
| Key | Type | Description | Example |
|---|---|---|---|
| maxAge | Number | Renvoie une version mise en cache de la page si elle est plus récente que cet âge en millisecondes. Si une version mise en cache de la page est plus ancienne que cette valeur, la page sera extraite. |
Remarque : Si vous n'avez pas besoin de données extrêmement récentes, l'activation de cette option peut accélérer vos extractions de 500 %.
mobile
| Key | Type | Description | Example |
|---|---|---|---|
| mobile | Boolean | Émuler le scraping depuis un appareil mobile. |
skipTlsVerification
| Key | Type | Description | Example |
|---|---|---|---|
| skipTlsVerification | Boolean | Ignorer la vérification du certificat TLS lors de l'envoi des requêtes. |
blockAds
| Key | Type | Description | Example |
|---|---|---|---|
| blockAds | Boolean | Active le blocage des publicités et des fenêtres contextuelles de cookies. |
removeBase64Images
| Key | Type | Description | Example |
|---|---|---|---|
| removeBase64Images | Boolean | Supprime toutes les images en base 64 de la sortie, ce qui peut être extrêmement long. Le texte alternatif de l'image reste dans la sortie, mais l'URL est remplacée par un espace réservé. |
parsePDF
| Key | Type | Description | Example |
|---|---|---|---|
| parsePDF | Boolean | Contrôle la manière dont les fichiers PDF sont traités lors du scraping. |
storeInCache
| Key | Type | Description | Example |
|---|---|---|---|
| storeInCache | Boolean | Si défini sur true, la page sera stockée dans l'index et le cache de Firecrawl. Définir cette valeur sur false est utile si votre activité de scraping peut soulever des préoccupations en matière de protection des données. L'utilisation de certains paramètres associés au scraping sensible (headers) forcera ce paramètre à false. |
zeroDataRetention
| Key | Type | Description | Example |
|---|---|---|---|
| zeroDataRetention | Boolean | Si défini sur true, cela activera la rétention de données nulle pour ce scrape (nécessite une configuration préalable sur Firecrawl). |
location
| Key | Type | Description | Example |
|---|---|---|---|
| location | Object | Paramètres de localisation géographique et de langue pour le scraping. |
onlyMainContent
| Key | Type | Description | Example |
|---|---|---|---|
| onlyMainContent | Boolean | Ne renvoyez que le contenu principal de la page, à l'exclusion des en-têtes, des barres de navigation, des pieds de page, etc. |
changeTrackingOptions
| Key | Type | Description | Example |
|---|---|---|---|
| changeTrackingOptions | Object | Configuration pour le suivi des modifications dans le contenu récupéré. |
Exemple :
Remarque : Pour des informations détaillées sur les options et les valeurs par défaut du scraper Firecrawl, consultez la Documentation de l'API Firecrawl.
tavilyScraperOptions
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyScraperOptions | Object | Options de configuration pour Tavily Extract (scraper). |
Sous-clés :
| Key | Type | Description | Example |
|---|---|---|---|
| extractDepth | String | La profondeur du processus d'extraction. "advanced" récupère davantage de données, y compris les tableaux et le contenu intégré, avec un meilleur taux de réussite, mais peut augmenter la latence. "basic" coûte 1 crédit pour 5 URL réussies, "advanced" coûte 2 crédits pour 5 URL réussies. | Options: "basic", "advanced". Default: "basic" |
| includeImages | Boolean | Inclure une liste d'images extraites des URLs dans la réponse. | Default: false |
| includeFavicon | Boolean | Inclure l'URL du favicon pour chaque résultat extrait. | Default: false |
| format | String | Le format du contenu de la page web extrait. "markdown" renvoie le contenu au format markdown. "text" renvoie du texte brut et peut augmenter la latence. | Options: "markdown", "text". Default: "markdown" |
| timeout | Number | Délai d'expiration en millisecondes. Contrôle le délai d'expiration HTTP côté client. Lorsqu'il est défini, il envoie également à Tavily un délai d'expiration d'extraction côté serveur converti en secondes et limité entre 1 et 60 s. | Default: 15000 for basic, 30000 for advanced |
Exemple :
Remarque : Pour des informations détaillées sur les options de l'API Tavily, consultez la Tavily API Documentation.
Rerankers
jinaApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| jinaApiKey | String | Nom de la variable d'environnement pour la clé API Jina. Si elle n'est pas définie dans .env, les utilisateurs seront invités à la fournir via l'interface utilisateur. | ${JINA_API_KEY} |
Note : Obtenez votre clé API sur Jina.ai
jinaApiUrl
| Key | Type | Description | Example |
|---|---|---|---|
| jinaApiUrl | String | Nom de la variable d'environnement pour l'URL de l'API Jina. S'il n'est pas défini dans .env, les utilisateurs seront invités à le fournir via l'interface utilisateur. | ${JINA_API_URL} |
Note : Ceci est facultatif et n'est nécessaire que si vous utilisez une instance Jina personnalisée.
cohereApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| cohereApiKey | String | Nom de la variable d'environnement pour la clé API Cohere. Si elle n'est pas définie dans .env, les utilisateurs seront invités à la fournir via l'interface utilisateur. | ${COHERE_API_KEY} |
Remarque : Obtenez votre clé API depuis le Cohere Dashboard
rerankerType
| Key | Type | Description | Example |
|---|---|---|---|
| rerankerType | String | Spécifie quel service de reranker utiliser. Définissez sur "none" pour ignorer le reranking. | Options: "jina", "cohere", "none" |
Paramètres généraux
scraperTimeout
| Key | Type | Description | Example |
|---|---|---|---|
| scraperTimeout | Integer | Délai d'attente en millisecondes pour les requêtes du scraper. Doit être un entier non négatif. | Default: 7500 |
safeSearch
| Key | Type | Description | Example |
|---|---|---|---|
| safeSearch | Number | Niveau de filtrage de la recherche sécurisée. 0 = DÉSACTIVÉ (aucun filtrage), 1 = MODÉRÉ (par défaut), 2 = STRICT (filtrage maximal). | Default: 1 (MODERATE) |
Note : Les niveaux de recherche sécurisée (Safe search) s'alignent sur les conventions standard des API de recherche. Le filtrage MODERATE est activé par défaut pour fournir un filtrage de contenu raisonnable tout en maintenant l'efficacité de la recherche. Tavily n'hérite pas de ce paramètre global par défaut ; utilisez tavilySearchOptions.safeSearch uniquement si votre compte Tavily prend en charge safe_search.
Notes
- Les clés API peuvent être configurées de deux manières :
- Définissez les variables d'environnement spécifiées dans la configuration YAML
- Si les variables d'environnement ne sont pas définies, les utilisateurs seront invités à fournir les clés API via l'interface utilisateur.
- La configuration prend en charge plusieurs services pour chaque composant (providers, scrapers, rerankers)
- Si aucun type de service spécifique n'est indiqué, le système essaiera tous les services disponibles dans cette catégorie.
- La recherche sécurisée (Safe search) propose trois niveaux de filtrage de contenu : OFF (0), MODERATE (1) et STRICT (2)
- Tavily n'hérite pas du paramètre global de recherche sécurisée par défaut ; définissez
tavilySearchOptions.safeSearchexplicitement uniquement lorsque votre compte Tavily prend en chargesafe_search. - Ne mettez jamais de clés API réelles dans la configuration YAML - utilisez uniquement les noms des variables d'environnement
Configuration de SearXNG
SearXNG est un méta-moteur de recherche axé sur la confidentialité que vous pouvez auto-héberger. Pour plus d'informations, consultez la documentation officielle de SearXNG.
Voici les étapes pour configurer votre propre instance SearXNG à utiliser avec LibreChat :
Utilisation de Docker Desktop
-
Rechercher l'image officielle de SearXNG
- Ouvrez Docker Desktop
- Recherchez
searxng/searxngdans l'onglet Images - Cliquez sur Run sur l'image officielle pour automatiquement télécharger et exécuter un conteneur de l'image
-
Exécution du conteneur
- Développez le menu déroulant Optional Settings dans le panneau qui apparaît une fois le téléchargement terminé.
- Définissez les détails de configuration souhaités (numéro de port, nom du conteneur, etc.)
- Cliquez sur Run pour démarrer le conteneur
-
Configurer SearXNG pour LibreChat
- Accédez à l'onglet
Filesdans Docker Desktop - Allez dans
/etc/searxng/settings.yaml - Ouvrir l'éditeur de fichiers
- Accédez à la section
formats - Ajoutez
jsoncomme format acceptable afin que LibreChat puisse communiquer avec votre instance - Enregistrez le fichier
- Accédez à l'onglet
-
Redémarrer le conteneur
- Redémarrez le conteneur pour que les modifications prennent effet
Guide vidéo :
Voici une vidéo pour vous guider tout au long du processus, du début à la fin, en environ une minute :
Remarque : Dans cet exemple, l'URL de l'instance est http://localhost:55011 (le numéro de port se trouve sous le nom du conteneur en haut à gauche à la fin de la vidéo)
Configuration de LibreChat pour utiliser SearXNG
Vous pouvez configurer SearXNG dans LibreChat via l'interface utilisateur ou par le biais de librechat.yaml.
Configuration de l'UI
-
Ouvrez le menu déroulant des outils dans la barre de saisie du chat
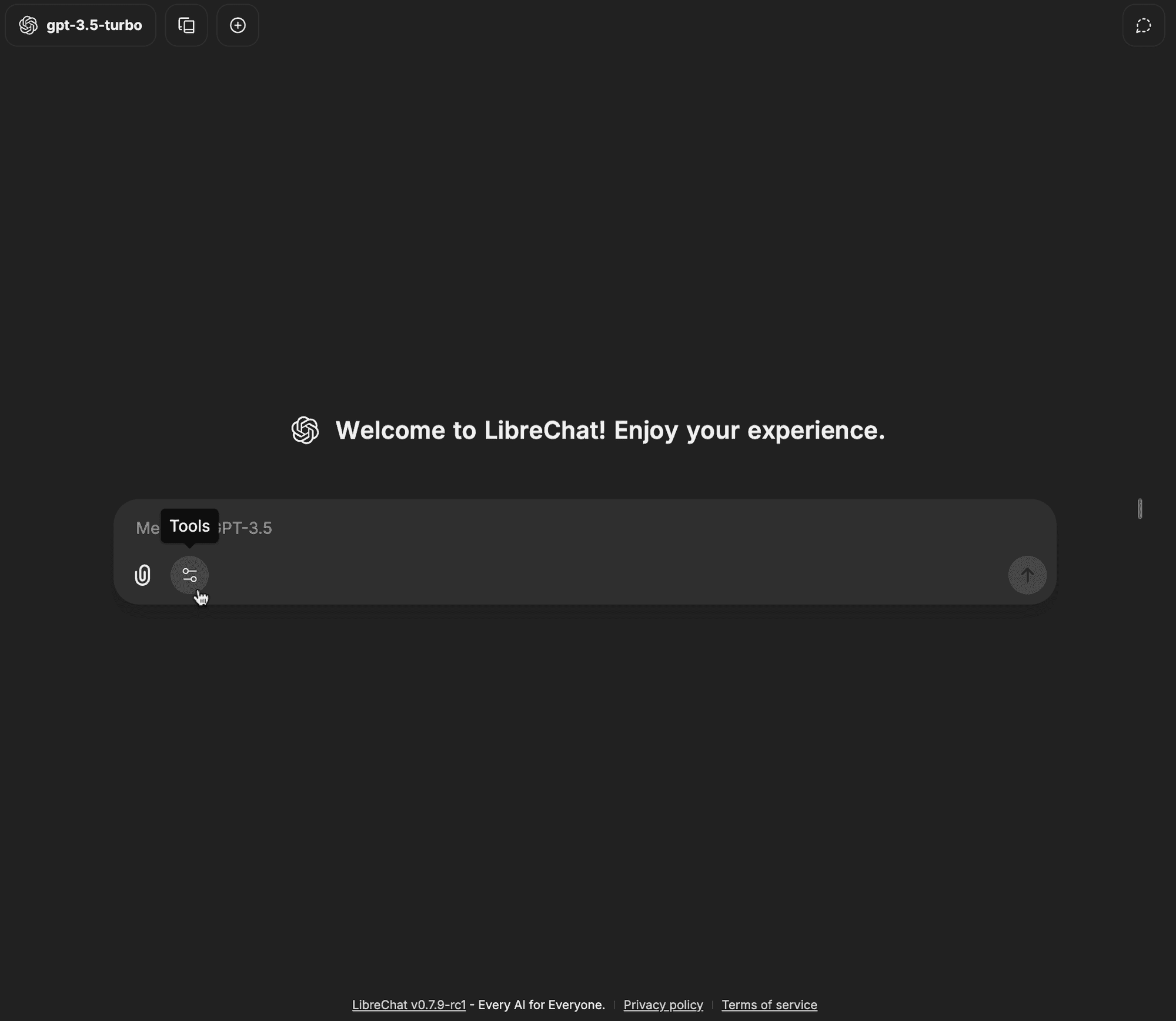
-
Cliquez sur l'icône d'engrenage à côté de Web Search
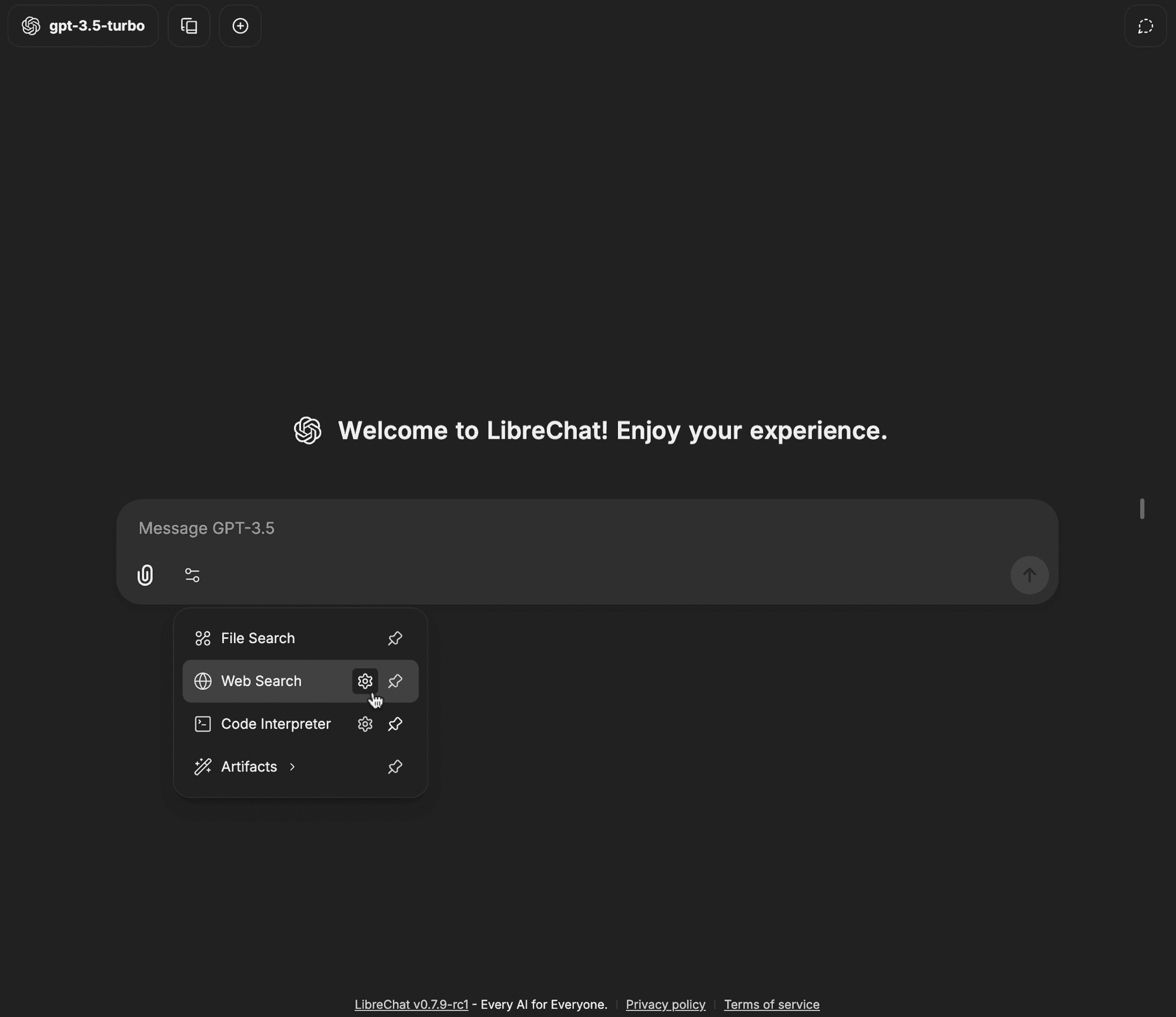
-
Sélectionnez SearXNG dans le menu déroulant Search Provider
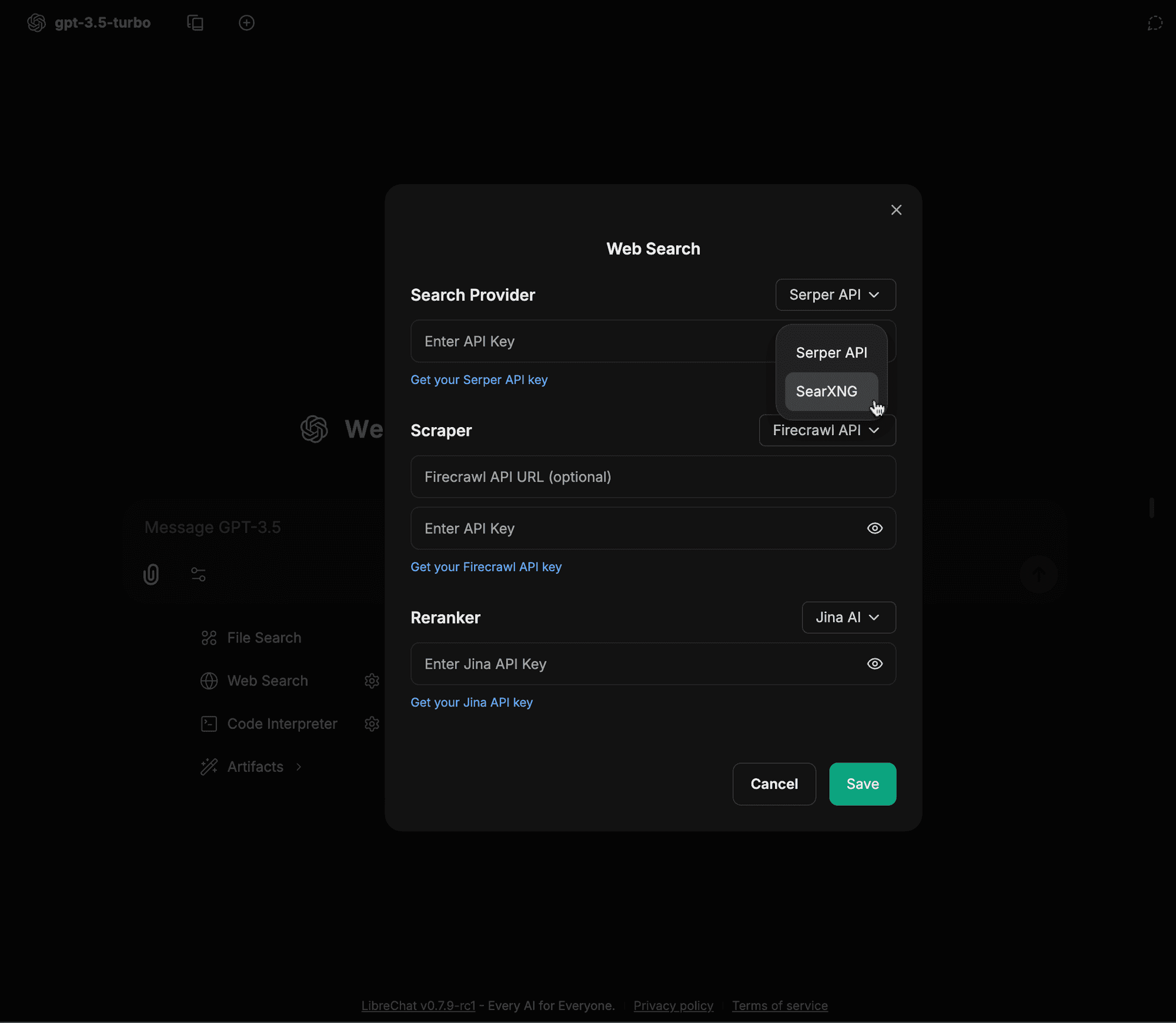
-
Saisissez vos détails de configuration (par ex. URL de l'instance, type de scraper, etc.) et cliquez sur enregistrer
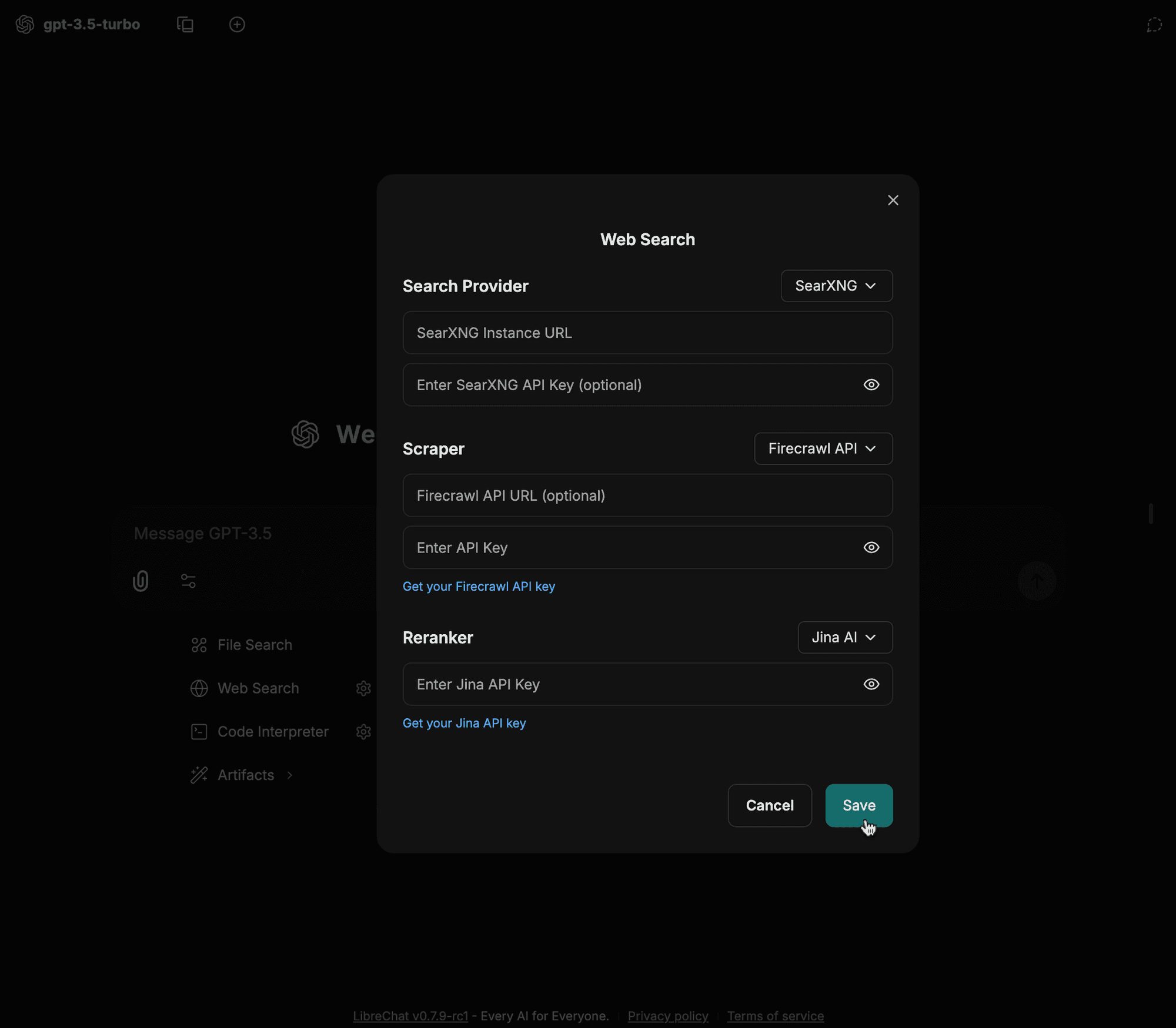
-
Cliquez sur l'option Web Search dans le menu déroulant des outils
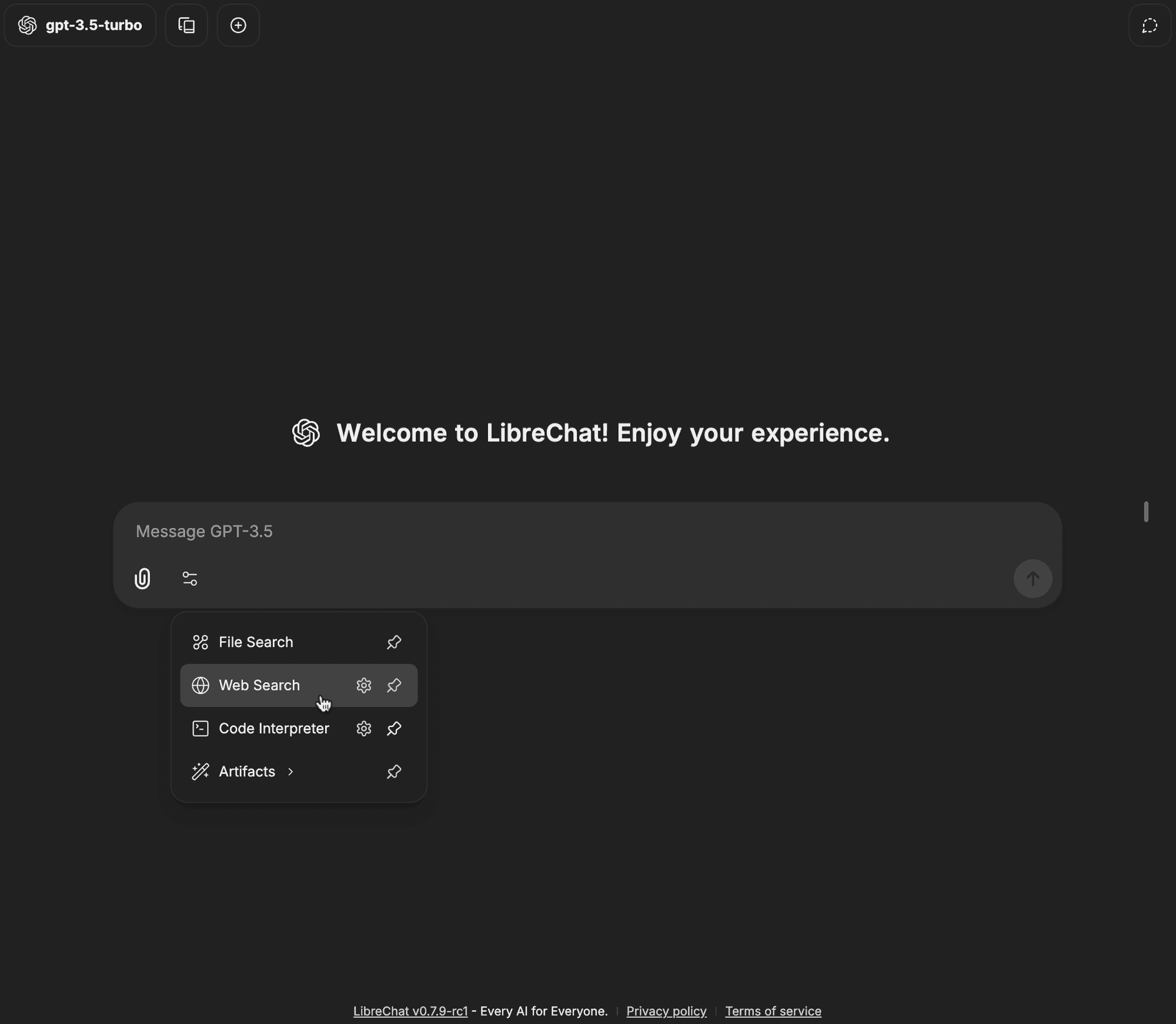
-
Le badge Web Search devrait maintenant être activé, ce qui signifie que vos requêtes peuvent désormais utiliser la fonctionnalité de recherche sur le Web
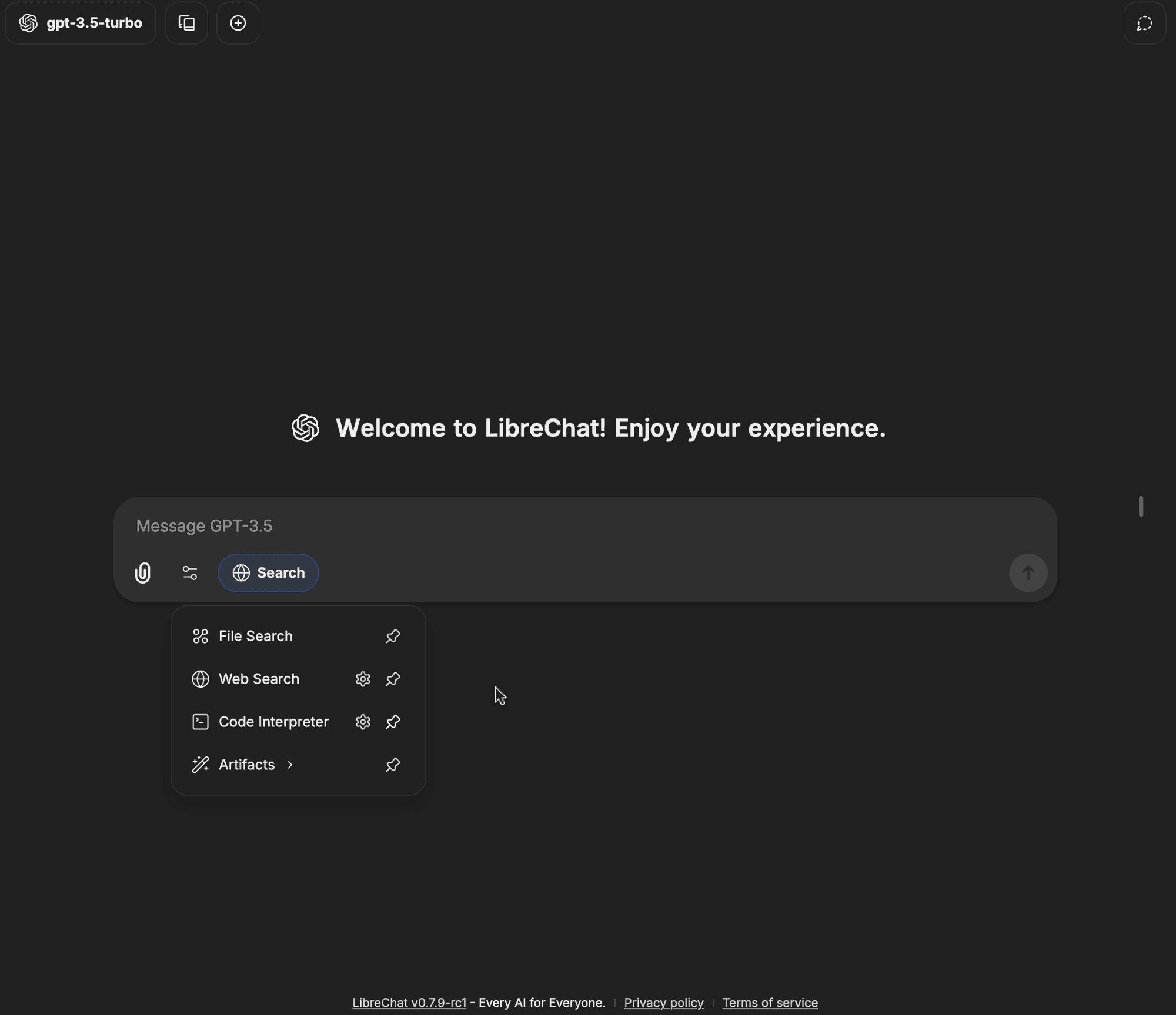
Que pensez-vous de ce guide ?