Configurazione della ricerca web
La configurazione webSearch ti consente di personalizzare la funzionalità di ricerca web all'interno di LibreChat, inclusi i provider di ricerca, gli scraper di contenuti e i reranker dei risultati.
Panoramica
La funzionalità di ricerca web è composta da tre componenti principali:
- Search Providers: Servizi che eseguono la ricerca web iniziale
- Scrapers: Servizi che estraggono contenuti dalle pagine web
- Rerankers: Servizi che riordinano i risultati di ricerca per una migliore pertinenza
Esempio
webSearch:
# Search Provider Configuration
serperApiKey: "${SERPER_API_KEY}"
searxngInstanceUrl: "${SEARXNG_INSTANCE_URL}"
searxngApiKey: "${SEARXNG_API_KEY}"
searchProvider: "serper" # Options: "serper", "searxng", "tavily"
# Tavily Configuration (search and/or scraper)
tavilyApiKey: "${TAVILY_API_KEY}"
# Optional: custom Tavily-compatible endpoints
tavilySearchUrl: "${TAVILY_SEARCH_URL}"
tavilyExtractUrl: "${TAVILY_EXTRACT_URL}"
# Scraper Configuration
firecrawlApiKey: "${FIRECRAWL_API_KEY}"
firecrawlApiUrl: "${FIRECRAWL_API_URL}"
firecrawlVersion: "${FIRECRAWL_VERSION}"
scraperProvider: "firecrawl" # Options: "firecrawl", "serper", "tavily"
# Reranker Configuration
jinaApiKey: "${JINA_API_KEY}"
jinaApiUrl: "${JINA_API_URL}"
cohereApiKey: "${COHERE_API_KEY}"
rerankerType: "jina" # Options: "jina", "cohere", "none"
# General Settings
scraperTimeout: 7500 # Timeout in milliseconds for scraper requests (default: 7500)
safeSearch: 1 # Options: 0 (OFF), 1 (MODERATE - default), 2 (STRICT)Provider di ricerca
searchProvider
| Key | Type | Description | Example |
|---|---|---|---|
| searchProvider | String | Specifica quale provider di ricerca utilizzare. | Options: "serper", "searxng", "tavily" |
serperApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| serperApiKey | String | Nome della variabile d'ambiente per la chiave API di Serper. Se non impostata nel file .env, agli utenti verrà richiesto di fornirla tramite l'interfaccia utente. | ${SERPER_API_KEY} |
Nota: Ottieni la tua chiave API da Serper.dev
searxngInstanceUrl
| Key | Type | Description | Example |
|---|---|---|---|
| searxngInstanceUrl | String | Nome della variabile d'ambiente per l'URL dell'istanza SearXNG. Se non impostato nel file .env, agli utenti verrà richiesto di fornirlo tramite l'interfaccia utente. | ${SEARXNG_INSTANCE_URL} |
searxngApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| searxngApiKey | String | Nome della variabile d'ambiente per la chiave API di SearXNG. Se non impostata nel file .env, agli utenti verrà richiesto di fornirla tramite l'interfaccia utente. | ${SEARXNG_API_KEY} |
Nota: Questo è facoltativo e necessario solo se la tua istanza SearXNG richiede l'autenticazione.
tavilyApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyApiKey | String | Nome della variabile d'ambiente per la chiave API di Tavily. Utilizzata sia per la ricerca che per lo scraper. Se non impostata nel file .env, agli utenti verrà richiesto di fornirla tramite l'interfaccia utente. | ${TAVILY_API_KEY} |
Nota: Ottieni la tua chiave API da Tavily
tavilySearchUrl
| Key | Type | Description | Example |
|---|---|---|---|
| tavilySearchUrl | String | Nome della variabile d'ambiente per un URL personalizzato dell'API di Tavily Search. Opzionale; se non impostato, viene utilizzata la ricerca ospitata da Tavily. | ${TAVILY_SEARCH_URL} |
tavilyExtractUrl
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyExtractUrl | String | Nome della variabile d'ambiente per un URL personalizzato dell'API Tavily Extract. Opzionale; se non impostato, viene utilizzato l'extract ospitato da Tavily. | ${TAVILY_EXTRACT_URL} |
tavilySearchOptions
| Key | Type | Description | Example |
|---|---|---|---|
| tavilySearchOptions | Object | Opzioni di configurazione per la ricerca Tavily. |
Sottochiavi:
| Key | Type | Description | Example |
|---|---|---|---|
| searchDepth | String | Controlla il compromesso tra rilevanza e latenza. "basic" restituisce un riepilogo NLP per URL. "advanced" restituisce molteplici snippet semanticamente rilevanti per URL (2 crediti API). "fast" bilancia velocità e rilevanza con snippet. "ultra-fast" minimizza la latenza con un riepilogo NLP. | Options: "basic", "advanced", "fast", "ultra-fast". Default: "basic" |
| maxResults | Number | Il numero massimo di risultati di ricerca da restituire. | Range: 1-20. Default: 5 |
| topic | String | La categoria della ricerca. "news" è utile per aggiornamenti in tempo reale. "finance" per dati finanziari. | Options: "general", "news", "finance". Default: "general" |
| includeImages | Boolean | Includi immagini nella risposta. Restituisce sia le immagini della query di primo livello che le immagini per singolo risultato. | Default: false |
| includeAnswer | Boolean or String | Includi una risposta generata da un LLM. "basic" o true per una risposta rapida, "advanced" per una risposta dettagliata. | Default: false |
| includeRawContent | Boolean or String | Includi contenuto HTML pulito e analizzato. "markdown" o true per il formato markdown, "text" per testo semplice. | Default: false |
| includeDomains | Array of Strings | Limita la ricerca a domini specifici. Massimo 300 domini. | |
| excludeDomains | Array of Strings | Escludi domini specifici dai risultati. Massimo 150 domini. | |
| timeRange | String | Filtro intervallo temporale basato sulla data di pubblicazione o di ultimo aggiornamento. | Options: "day", "week", "month", "year" |
| includeImageDescriptions | Boolean | Quando includeImages è true, aggiungi anche un testo descrittivo per ogni immagine. | Default: false |
| includeFavicon | Boolean | Includi l'URL della favicon per ogni risultato di ricerca. | Default: false |
| chunksPerSource | Number | Numero massimo di chunk di contenuto rilevanti per fonte. Disponibile solo quando searchDepth è impostato su "advanced". | Range: 1-3. Default: 3 |
| safeSearch | Boolean | Override opzionale safe_search di Tavily per le richieste di ricerca Tavily. Omesso per impostazione predefinita; true potrebbe richiedere Tavily Enterprise. | Default: omitted |
| timeout | Number | Timeout della richiesta HTTP lato client in millisecondi. Controlla quanto tempo attendere la risposta dell'API Tavily prima di rinunciare. | Default: 15000 |
Scrapers
firecrawlApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlApiKey | String | Nome della variabile d'ambiente per la chiave API di Firecrawl. Se non impostata nel file .env, agli utenti verrà richiesto di fornirla tramite l'interfaccia utente. | ${FIRECRAWL_API_KEY} |
Nota: Ottieni la tua chiave API da Firecrawl.dev
firecrawlApiUrl
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlApiUrl | String | Nome della variabile d'ambiente per l'URL dell'API Firecrawl. Se non impostato nel file .env, agli utenti verrà richiesto di fornirlo tramite l'interfaccia utente. | ${FIRECRAWL_API_URL} |
Nota: Questo è facoltativo e necessario solo se si utilizza un'istanza personalizzata di Firecrawl.
firecrawlVersion
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlVersion | String | Nome della variabile d'ambiente per la versione dell'API Firecrawl (v0 o v1). | ${FIRECRAWL_VERSION} |
scraperProvider
| Key | Type | Description | Example |
|---|---|---|---|
| scraperProvider | String | Specifica quale servizio di scraper utilizzare. | Options: "firecrawl", "serper", "tavily" |
firecrawlOptions
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlOptions | Object | Opzioni di configurazione avanzate per lo scraper Firecrawl. |
Sottochiavi:
formats
| Key | Type | Description | Example |
|---|---|---|---|
| formats | Array of Strings | Formati da includere nell'output. |
includeTags
| Key | Type | Description | Example |
|---|---|---|---|
| includeTags | Array of Strings | Tag da includere nell'output. |
excludeTags
| Key | Type | Description | Example |
|---|---|---|---|
| excludeTags | Array of Strings | Tag da escludere dall'output. |
headers
| Key | Type | Description | Example |
|---|---|---|---|
| headers | Object | Intestazioni da inviare con la richiesta. Possono essere utilizzate per inviare cookie, user-agent, ecc. |
waitFor
| Key | Type | Description | Example |
|---|---|---|---|
| waitFor | Number | Specifica un ritardo in millisecondi prima di recuperare il contenuto, consentendo alla pagina tempo sufficiente per il caricamento. |
timeout
| Key | Type | Description | Example |
|---|---|---|---|
| timeout | Integer | Timeout in millisecondi per la richiesta di scraping. Deve essere un numero intero non negativo. | Default: 7500 |
maxAge
| Key | Type | Description | Example |
|---|---|---|---|
| maxAge | Number | Restituisce una versione memorizzata nella cache della pagina se è più recente di questa età in millisecondi. Se una versione memorizzata nella cache della pagina è più vecchia di questo valore, la pagina verrà sottoposta a scraping. |
Nota: Se non hai bisogno di dati estremamente aggiornati, abilitare questa opzione può velocizzare i tuoi scrape del 500%.
mobile
| Key | Type | Description | Example |
|---|---|---|---|
| mobile | Boolean | Emula lo scraping da un dispositivo mobile. |
skipTlsVerification
| Key | Type | Description | Example |
|---|---|---|---|
| skipTlsVerification | Boolean | Salta la verifica del certificato TLS durante l'esecuzione delle richieste. |
blockAds
| Key | Type | Description | Example |
|---|---|---|---|
| blockAds | Boolean | Abilita il blocco degli annunci e dei popup dei cookie. |
removeBase64Images
| Key | Type | Description | Example |
|---|---|---|---|
| removeBase64Images | Boolean | Rimuove tutte le immagini in base 64 dall'output, che potrebbero essere eccessivamente lunghe. Il testo alternativo dell'immagine rimane nell'output, ma l'URL viene sostituito con un segnaposto. |
parsePDF
| Key | Type | Description | Example |
|---|---|---|---|
| parsePDF | Boolean | Controlla come vengono elaborati i file PDF durante lo scraping. |
storeInCache
| Key | Type | Description | Example |
|---|---|---|---|
| storeInCache | Boolean | Se impostato su true, la pagina verrà archiviata nell'indice e nella cache di Firecrawl. Impostarlo su false è utile se la tua attività di scraping potrebbe sollevare problemi di protezione dei dati. L'utilizzo di alcuni parametri associati allo scraping sensibile (headers) forzerà questo parametro su false. |
zeroDataRetention
| Key | Type | Description | Example |
|---|---|---|---|
| zeroDataRetention | Boolean | Se impostato su true, verrà abilitata la conservazione zero dei dati per questo scrape (richiede una configurazione preliminare su Firecrawl). |
location
| Key | Type | Description | Example |
|---|---|---|---|
| location | Object | Posizione geografica e impostazioni della lingua per lo scraping. |
onlyMainContent
| Key | Type | Description | Example |
|---|---|---|---|
| onlyMainContent | Boolean | Restituisci solo il contenuto principale della pagina, escludendo intestazioni, barre di navigazione, piè di pagina, ecc. |
changeTrackingOptions
| Key | Type | Description | Example |
|---|---|---|---|
| changeTrackingOptions | Object | Configurazione per il tracciamento delle modifiche nei contenuti estratti. |
Esempio:
webSearch:
firecrawlApiKey: "${FIRECRAWL_API_KEY}"
firecrawlOptions:
formats: ["markdown", "rawHtml"]
includeTags: ["main", "article", ".content"]
excludeTags: ["nav", "footer", ".ads"]
waitFor: 2000
timeout: 10000
mobile: false
blockAds: true
onlyMainContent: true
location:
country: "US"
languages: ["en"]Nota: Per informazioni dettagliate sulle opzioni e sui valori predefiniti dello scraper Firecrawl, consulta la Firecrawl API Documentation.
tavilyScraperOptions
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyScraperOptions | Object | Opzioni di configurazione per Tavily Extract (scraper). |
Sottochiavi:
| Key | Type | Description | Example |
|---|---|---|---|
| extractDepth | String | La profondità del processo di estrazione. "advanced" recupera più dati, incluse tabelle e contenuti incorporati, con un tasso di successo maggiore, ma può aumentare la latenza. "basic" costa 1 credito ogni 5 URL riusciti, "advanced" costa 2 crediti ogni 5 URL riusciti. | Options: "basic", "advanced". Default: "basic" |
| includeImages | Boolean | Includi un elenco di immagini estratte dagli URL nella risposta. | Default: false |
| includeFavicon | Boolean | Includi l'URL della favicon per ogni risultato estratto. | Default: false |
| format | String | Il formato del contenuto della pagina web estratto. "markdown" restituisce il contenuto in formato markdown. "text" restituisce testo semplice e potrebbe aumentare la latenza. | Options: "markdown", "text". Default: "markdown" |
| timeout | Number | Timeout in millisecondi. Controlla il timeout HTTP lato client. Quando impostato, invia anche a Tavily un timeout di estrazione lato server convertito in secondi e limitato a 1-60s. | Default: 15000 for basic, 30000 for advanced |
Esempio:
webSearch:
searchProvider: tavily
scraperProvider: tavily
tavilyApiKey: "${TAVILY_API_KEY}"
# Optional: custom Tavily-compatible endpoints
# tavilySearchUrl: "${TAVILY_SEARCH_URL}"
# tavilyExtractUrl: "${TAVILY_EXTRACT_URL}"
tavilySearchOptions:
searchDepth: basic
maxResults: 5
topic: general
tavilyScraperOptions:
extractDepth: basicNota: Per informazioni dettagliate sulle opzioni dell'API Tavily, consulta la Tavily API Documentation.
Rerankers
jinaApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| jinaApiKey | String | Nome della variabile d'ambiente per la chiave API di Jina. Se non impostata nel file .env, agli utenti verrà richiesto di fornirla tramite l'interfaccia utente. | ${JINA_API_KEY} |
Nota: Ottieni la tua chiave API da Jina.ai
jinaApiUrl
| Key | Type | Description | Example |
|---|---|---|---|
| jinaApiUrl | String | Nome della variabile d'ambiente per l'URL dell'API Jina. Se non impostato nel file .env, agli utenti verrà richiesto di fornirlo tramite l'interfaccia utente. | ${JINA_API_URL} |
Nota: Questo è facoltativo e necessario solo se si utilizza un'istanza Jina personalizzata.
cohereApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| cohereApiKey | String | Nome della variabile d'ambiente per la chiave API di Cohere. Se non impostata nel file .env, agli utenti verrà richiesto di fornirla tramite l'interfaccia utente. | ${COHERE_API_KEY} |
Nota: Ottieni la tua chiave API dalla Dashboard di Cohere
rerankerType
| Key | Type | Description | Example |
|---|---|---|---|
| rerankerType | String | Specifica quale servizio di reranker utilizzare. Impostare su "none" per saltare il reranking. | Options: "jina", "cohere", "none" |
Impostazioni generali
scraperTimeout
| Key | Type | Description | Example |
|---|---|---|---|
| scraperTimeout | Integer | Timeout in millisecondi per le richieste dello scraper. Deve essere un numero intero non negativo. | Default: 7500 |
safeSearch
| Key | Type | Description | Example |
|---|---|---|---|
| safeSearch | Number | Livello di filtro della ricerca sicura. 0 = OFF (nessun filtro), 1 = MODERATE (predefinito), 2 = STRICT (filtro massimo). | Default: 1 (MODERATE) |
Nota: I livelli di ricerca sicura (safe search) si allineano alle convenzioni standard delle API di ricerca. Il filtro MODERATE è abilitato per impostazione predefinita per fornire un filtraggio dei contenuti ragionevole mantenendo al contempo l'efficacia della ricerca. Tavily non eredita questa impostazione globale per impostazione predefinita; utilizzare tavilySearchOptions.safeSearch solo se il proprio account Tavily supporta safe_search.
Note
- Le API keys possono essere configurate in due modi:
- Imposta le variabili d'ambiente specificate nella configurazione YAML
- Se le variabili d'ambiente non sono impostate, agli utenti verrà richiesto di fornire le API key tramite l'interfaccia utente.
- La configurazione supporta molteplici servizi per ogni componente (providers, scrapers, rerankers)
- Se non viene specificato un tipo di servizio particolare, il sistema proverà tutti i servizi disponibili in quella categoria
- Safe search fornisce tre livelli di filtro dei contenuti: OFF (0), MODERATE (1) e STRICT (2)
- Tavily non eredita l'impostazione globale di ricerca sicura per impostazione predefinita; imposta
tavilySearchOptions.safeSearchesplicitamente solo quando il tuo account Tavily supportasafe_search - Non inserire mai chiavi API reali nella configurazione YAML: utilizza solo i nomi delle variabili d'ambiente
Configurazione di SearXNG
SearXNG è un meta-motore di ricerca incentrato sulla privacy che puoi ospitare autonomamente. Per ulteriori informazioni, consulta la documentazione ufficiale di SearXNG.
Ecco i passaggi per configurare la tua istanza SearXNG da utilizzare con LibreChat:
Utilizzo di Docker Desktop
-
Cerca l'immagine ufficiale di SearXNG
- Apri Docker Desktop
- Cerca
searxng/searxngnella scheda Images - Fai clic su Run sull'immagine ufficiale per scaricare ed eseguire automaticamente un container dell'immagine
-
Esecuzione del container
- Espandi il menu a tendina Optional Settings nel pannello successivo che appare una volta completato il download.
- Imposta i dettagli di configurazione desiderati (numero di porta, nome del container, ecc.)
- Fai clic su Run per avviare il container
-
Configurare SearXNG per LibreChat
- Vai alla scheda
Filesin Docker Desktop - Vai a
/etc/searxng/settings.yaml - Apri l'editor di file
- Passa alla sezione
formats - Aggiungi
jsoncome formato accettabile in modo che LibreChat possa comunicare con la tua istanza - Salva il file
- Vai alla scheda
-
Riavvia il container
- Riavvia il container affinché le modifiche abbiano effetto
Guida video:
Ecco un video per guidarti attraverso il processo dall'inizio alla fine in circa un minuto:
Nota: In questo esempio, l'URL dell'istanza è http://localhost:55011 (il numero di porta si trova sotto il nome del container in alto a sinistra alla fine del video)
Configurazione di LibreChat per utilizzare SearXNG
Puoi configurare SearXNG in LibreChat dall'interfaccia utente o tramite librechat.yaml.
Configurazione dell'interfaccia utente
-
Apri il menu a discesa degli strumenti nella barra di input della chat
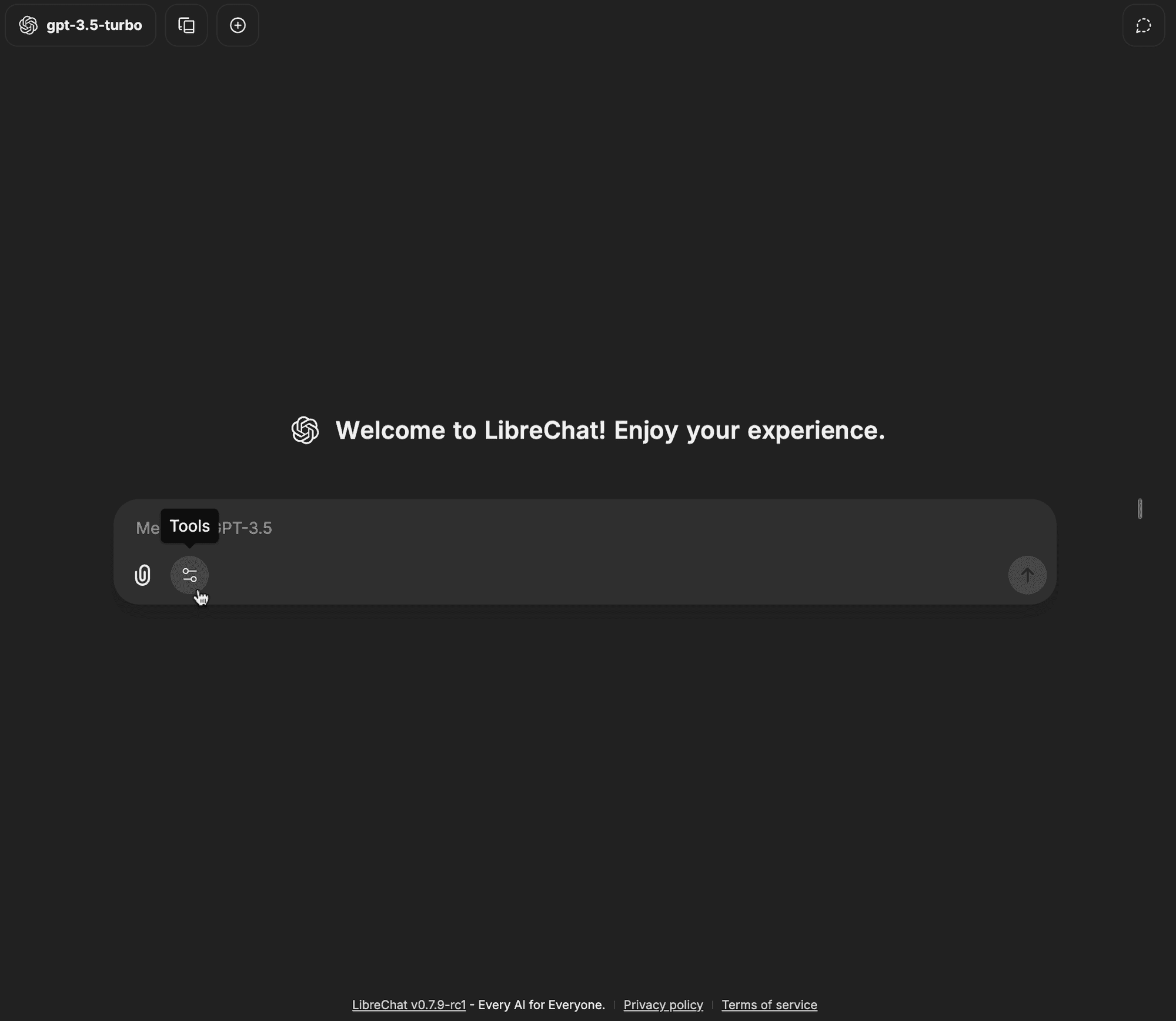
-
Fai clic sull'icona dell'ingranaggio accanto a Web Search
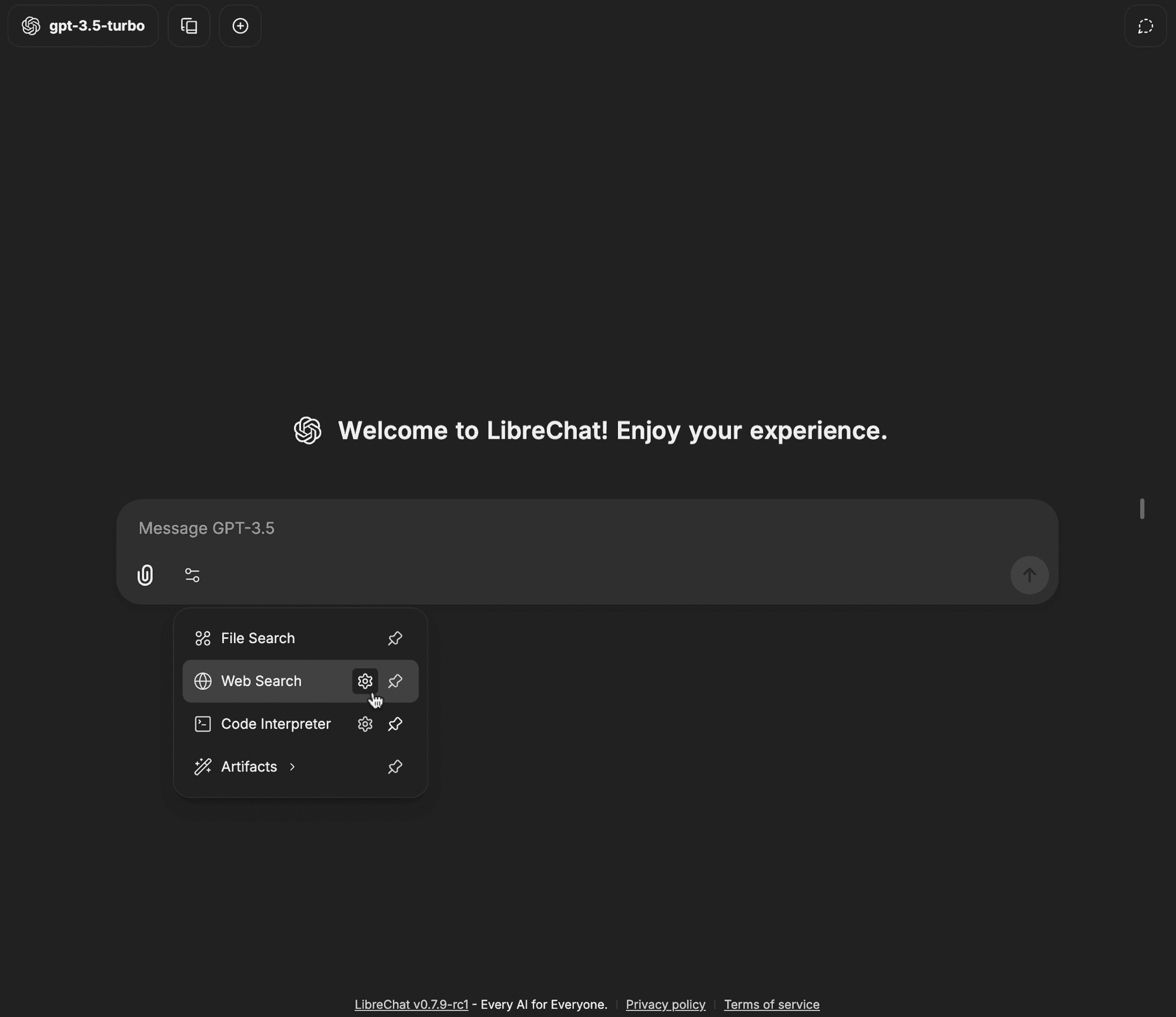
-
Seleziona SearXNG dal menu a tendina Search Provider
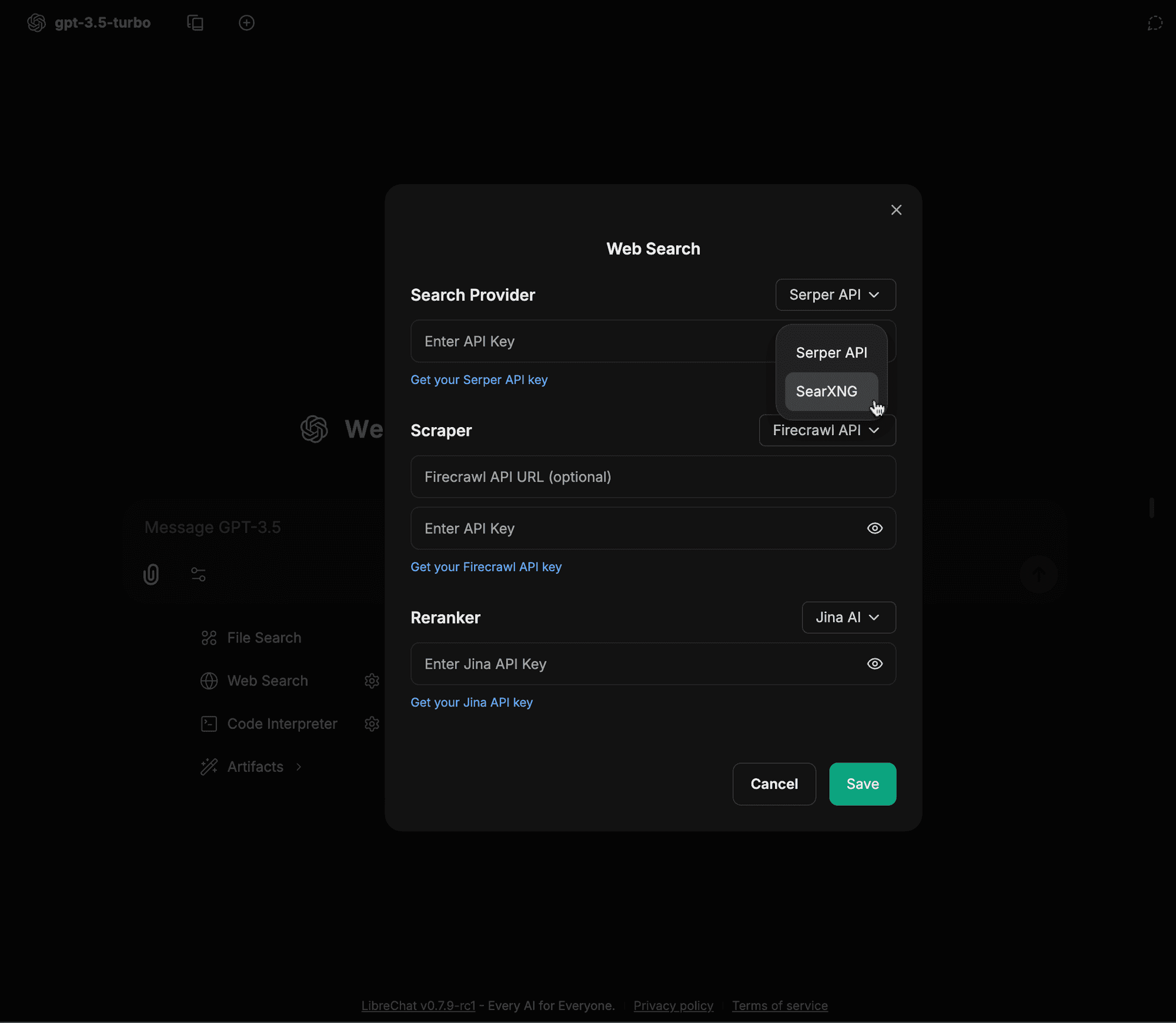
-
Inserisci i dettagli della tua configurazione (ad es. URL dell'istanza, tipo di scraper, ecc.) e fai clic su salva
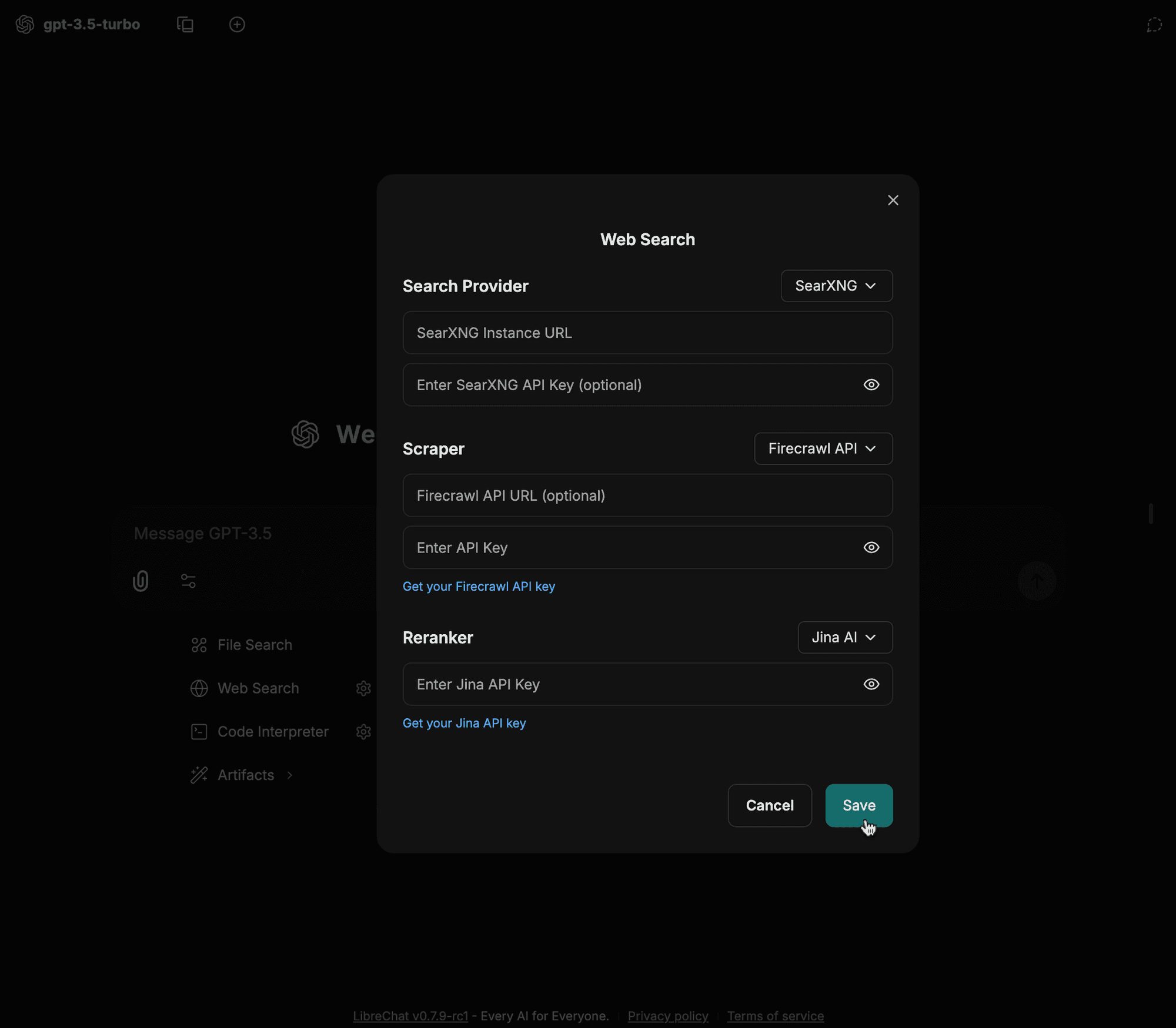
-
Fai clic sull'opzione Web Search nel menu a discesa degli strumenti
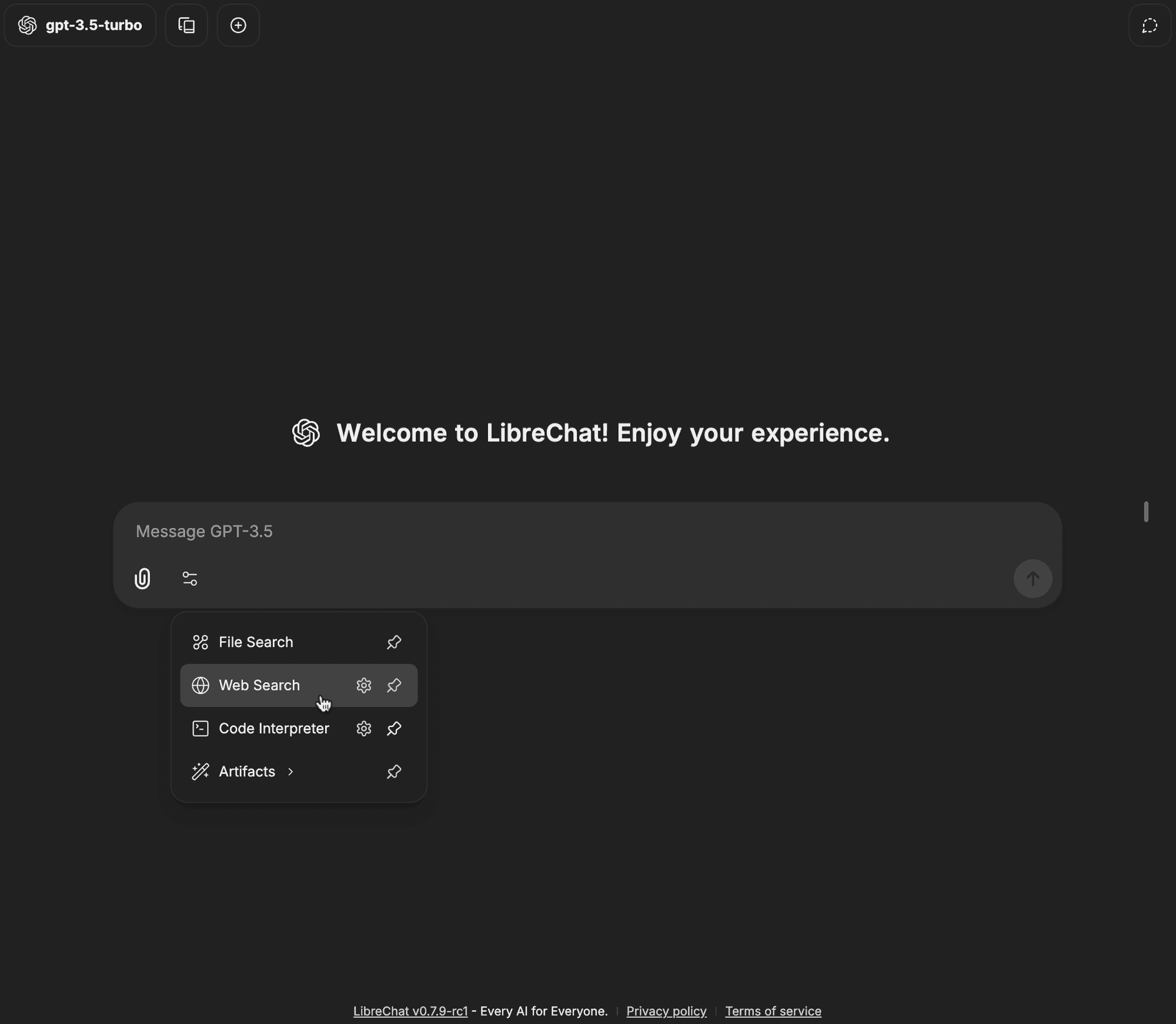
-
Il badge di Web Search dovrebbe ora essere abilitato, il che significa che le tue query possono ora utilizzare la funzionalità di ricerca web
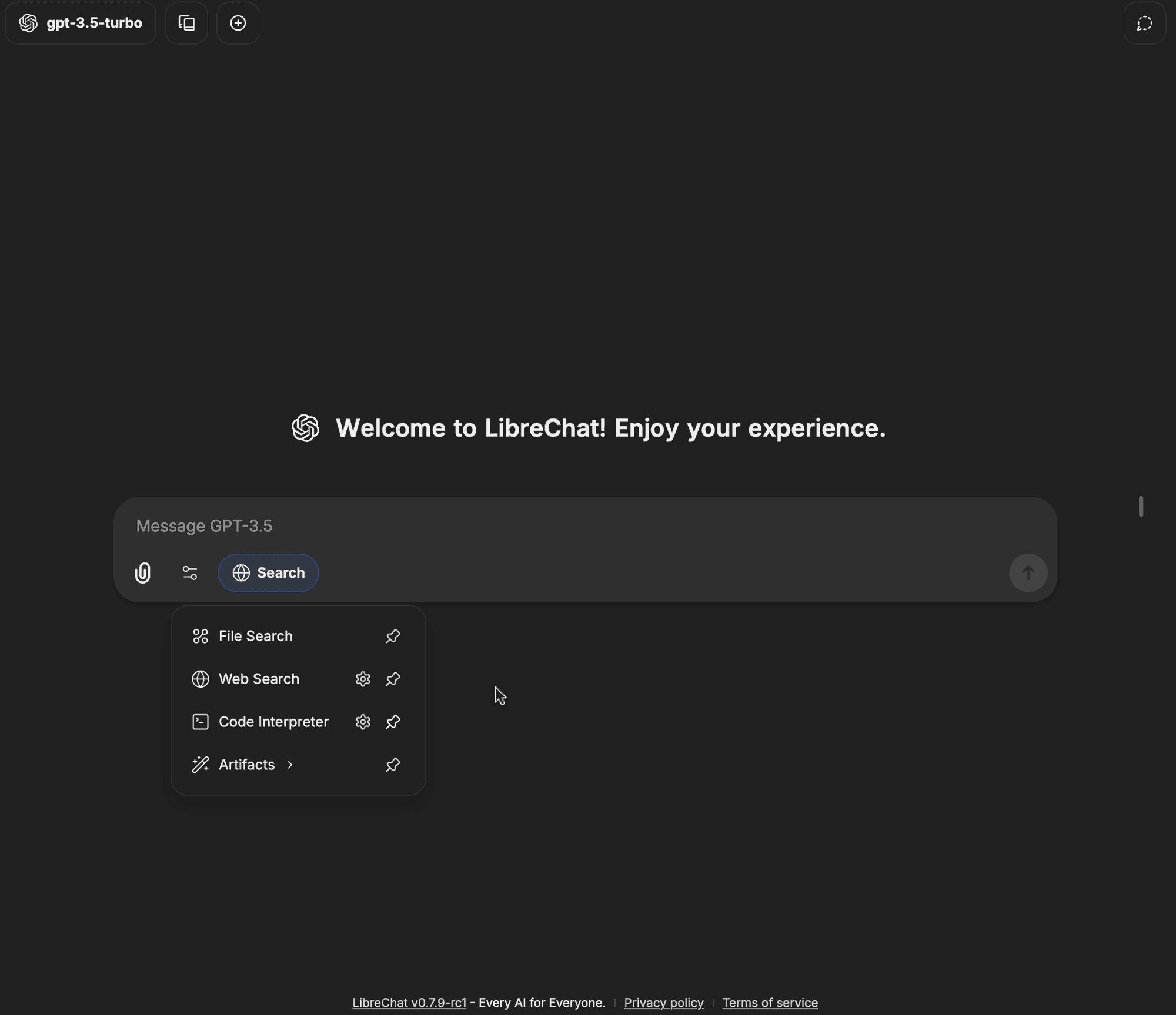
Com’è questa guida?