Web Search Configuration
The webSearch configuration allows you to customize the web search functionality within LibreChat, including search providers, content scrapers, and result rerankers.
Overview
The web search feature consists of three main components:
- Search Providers: Services that perform the initial web search
- Scrapers: Services that extract content from web pages
- Rerankers: Services that reorder search results for better relevance
Example
Search Providers
searchProvider
| Key | Type | Description | Example |
|---|---|---|---|
| searchProvider | String | Specifies which search provider to use. | Options: "serper", "searxng", "tavily" |
serperApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| serperApiKey | String | Environment variable name for the Serper API key. If not set in .env, users will be prompted to provide it via UI. | ${SERPER_API_KEY} |
Note: Get your API key from Serper.dev
searxngInstanceUrl
| Key | Type | Description | Example |
|---|---|---|---|
| searxngInstanceUrl | String | Environment variable name for the SearXNG instance URL. If not set in .env, users will be prompted to provide it via UI. | ${SEARXNG_INSTANCE_URL} |
searxngApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| searxngApiKey | String | Environment variable name for the SearXNG API key. If not set in .env, users will be prompted to provide it via UI. | ${SEARXNG_API_KEY} |
Note: This is optional and only needed if your SearXNG instance requires authentication.
tavilyApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyApiKey | String | Environment variable name for the Tavily API key. Used for both search and scraper. If not set in .env, users will be prompted to provide it via UI. | ${TAVILY_API_KEY} |
Note: Get your API key from Tavily
tavilySearchUrl
| Key | Type | Description | Example |
|---|---|---|---|
| tavilySearchUrl | String | Environment variable name for a custom Tavily Search API URL. Optional; defaults to Tavily hosted search when unset. | ${TAVILY_SEARCH_URL} |
tavilyExtractUrl
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyExtractUrl | String | Environment variable name for a custom Tavily Extract API URL. Optional; defaults to Tavily hosted extract when unset. | ${TAVILY_EXTRACT_URL} |
tavilySearchOptions
| Key | Type | Description | Example |
|---|---|---|---|
| tavilySearchOptions | Object | Configuration options for Tavily search. |
Subkeys:
| Key | Type | Description | Example |
|---|---|---|---|
| searchDepth | String | Controls relevance vs latency tradeoff. "basic" returns one NLP summary per URL. "advanced" returns multiple semantically relevant snippets per URL (2 API credits). "fast" balances speed and relevance with snippets. "ultra-fast" minimizes latency with one NLP summary. | Options: "basic", "advanced", "fast", "ultra-fast". Default: "basic" |
| maxResults | Number | The maximum number of search results to return. | Range: 1-20. Default: 5 |
| topic | String | The category of the search. "news" is useful for real-time updates. "finance" for financial data. | Options: "general", "news", "finance". Default: "general" |
| includeImages | Boolean | Include images in the response. Returns both top-level query images and per-result images. | Default: false |
| includeAnswer | Boolean or String | Include an LLM-generated answer. "basic" or true for a quick answer, "advanced" for a detailed answer. | Default: false |
| includeRawContent | Boolean or String | Include cleaned and parsed HTML content. "markdown" or true for markdown format, "text" for plain text. | Default: false |
| includeDomains | Array of Strings | Restrict search to specific domains. Maximum 300 domains. | |
| excludeDomains | Array of Strings | Exclude specific domains from results. Maximum 150 domains. | |
| timeRange | String | Time range filter based on publish or last updated date. | Options: "day", "week", "month", "year" |
| includeImageDescriptions | Boolean | When includeImages is true, also add a descriptive text for each image. | Default: false |
| includeFavicon | Boolean | Include the favicon URL for each search result. | Default: false |
| chunksPerSource | Number | Maximum number of relevant content chunks per source. Only available when searchDepth is "advanced". | Range: 1-3. Default: 3 |
| safeSearch | Boolean | Optional Tavily safe_search override for Tavily Search requests. Omitted by default; true may require Tavily Enterprise. | Default: omitted |
| timeout | Number | Client-side HTTP request timeout in milliseconds. Controls how long to wait for the Tavily API to respond before giving up. | Default: 15000 |
Scrapers
firecrawlApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlApiKey | String | Environment variable name for the Firecrawl API key. If not set in .env, users will be prompted to provide it via UI. | ${FIRECRAWL_API_KEY} |
Note: Get your API key from Firecrawl.dev
firecrawlApiUrl
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlApiUrl | String | Environment variable name for the Firecrawl API URL. If not set in .env, users will be prompted to provide it via UI. | ${FIRECRAWL_API_URL} |
Note: This is optional and only needed if you're using a custom Firecrawl instance.
firecrawlVersion
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlVersion | String | Environment variable name for the Firecrawl API version (v0 or v1). | ${FIRECRAWL_VERSION} |
scraperProviderider
| Key | Type | Description | Example |
|---|---|---|---|
| scraperProvider | String | Specifies which scraper service to use. | Options: "firecrawl", "serper", "tavily" |
firecrawlOptions
| Key | Type | Description | Example |
|---|---|---|---|
| firecrawlOptions | Object | Advanced configuration options for Firecrawl scraper. |
Subkeys:
formats
| Key | Type | Description | Example |
|---|---|---|---|
| formats | Array of Strings | Formats to include in the output. |
includeTags
| Key | Type | Description | Example |
|---|---|---|---|
| includeTags | Array of Strings | Tags to include in the output. |
excludeTags
| Key | Type | Description | Example |
|---|---|---|---|
| excludeTags | Array of Strings | Tags to exclude from the output. |
headers
| Key | Type | Description | Example |
|---|---|---|---|
| headers | Object | Headers to send with the request. Can be used to send cookies, user-agent, etc. |
waitFor
| Key | Type | Description | Example |
|---|---|---|---|
| waitFor | Number | Specify a delay in milliseconds before fetching the content, allowing the page sufficient time to load. |
timeout
| Key | Type | Description | Example |
|---|---|---|---|
| timeout | Integer | Timeout in milliseconds for the scraping request. Must be a non-negative integer. | Default: 7500 |
maxAge
| Key | Type | Description | Example |
|---|---|---|---|
| maxAge | Number | Returns a cached version of the page if it is younger than this age in milliseconds. If a cached version of the page is older than this value, the page will be scraped. |
Note: If you do not need extremely fresh data, enabling this can speed up your scrapes by 500%.
mobile
| Key | Type | Description | Example |
|---|---|---|---|
| mobile | Boolean | Emulate scraping from a mobile device. |
skipTlsVerification
| Key | Type | Description | Example |
|---|---|---|---|
| skipTlsVerification | Boolean | Skip TLS certificate verification when making requests. |
blockAds
| Key | Type | Description | Example |
|---|---|---|---|
| blockAds | Boolean | Enables ad-blocking and cookie popup blocking. |
removeBase64Images
| Key | Type | Description | Example |
|---|---|---|---|
| removeBase64Images | Boolean | Removes all base 64 images from the output, which may be overwhelmingly long. The image's alt text remains in the output, but the URL is replaced with a placeholder. |
parsePDF
| Key | Type | Description | Example |
|---|---|---|---|
| parsePDF | Boolean | Controls how PDF files are processed during scraping. |
storeInCache
| Key | Type | Description | Example |
|---|---|---|---|
| storeInCache | Boolean | If true, the page will be stored in the Firecrawl index and cache. Setting this to false is useful if your scraping activity may have data protection concerns. Using some parameters associated with sensitive scraping (headers) will force this parameter to be false. |
zeroDataRetention
| Key | Type | Description | Example |
|---|---|---|---|
| zeroDataRetention | Boolean | If true, this will enable zero data retention for this scrape (requires prior setup on Firecrawl). |
location
| Key | Type | Description | Example |
|---|---|---|---|
| location | Object | Geographic location and language settings for scraping. |
onlyMainContent
| Key | Type | Description | Example |
|---|---|---|---|
| onlyMainContent | Boolean | Only return the main content of the page excluding headers, navs, footers, etc. |
changeTrackingOptions
| Key | Type | Description | Example |
|---|---|---|---|
| changeTrackingOptions | Object | Configuration for tracking changes in scraped content. |
Example:
Note: For detailed information about Firecrawl scraper options and defaults, see the Firecrawl API Documentation.
tavilyScraperOptions
| Key | Type | Description | Example |
|---|---|---|---|
| tavilyScraperOptions | Object | Configuration options for Tavily Extract (scraper). |
Subkeys:
| Key | Type | Description | Example |
|---|---|---|---|
| extractDepth | String | The depth of the extraction process. "advanced" retrieves more data including tables and embedded content with higher success but may increase latency. "basic" costs 1 credit per 5 successful URLs, "advanced" costs 2 credits per 5 successful URLs. | Options: "basic", "advanced". Default: "basic" |
| includeImages | Boolean | Include a list of images extracted from the URLs in the response. | Default: false |
| includeFavicon | Boolean | Include the favicon URL for each extracted result. | Default: false |
| format | String | The format of the extracted web page content. "markdown" returns content in markdown format. "text" returns plain text and may increase latency. | Options: "markdown", "text". Default: "markdown" |
| timeout | Number | Timeout in milliseconds. Controls the client-side HTTP timeout. When set, it also sends Tavily a server-side extraction timeout converted to seconds and clamped to 1-60s. | Default: 15000 for basic, 30000 for advanced |
Example:
Note: For detailed information about Tavily API options, see the Tavily API Documentation.
Rerankers
jinaApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| jinaApiKey | String | Environment variable name for the Jina API key. If not set in .env, users will be prompted to provide it via UI. | ${JINA_API_KEY} |
Note: Get your API key from Jina.ai
jinaApiUrl
| Key | Type | Description | Example |
|---|---|---|---|
| jinaApiUrl | String | Environment variable name for the Jina API URL. If not set in .env, users will be prompted to provide it via UI. | ${JINA_API_URL} |
Note: This is optional and only needed if you're using a custom Jina instance.
cohereApiKey
| Key | Type | Description | Example |
|---|---|---|---|
| cohereApiKey | String | Environment variable name for the Cohere API key. If not set in .env, users will be prompted to provide it via UI. | ${COHERE_API_KEY} |
Note: Get your API key from Cohere Dashboard
rerankerType
| Key | Type | Description | Example |
|---|---|---|---|
| rerankerType | String | Specifies which reranker service to use. Set to "none" to skip reranking. | Options: "jina", "cohere", "none" |
General Settings
scraperTimeout
| Key | Type | Description | Example |
|---|---|---|---|
| scraperTimeout | Integer | Timeout in milliseconds for scraper requests. Must be a non-negative integer. | Default: 7500 |
safeSearch
| Key | Type | Description | Example |
|---|---|---|---|
| safeSearch | Number | Safe search filtering level. 0 = OFF (no filtering), 1 = MODERATE (default), 2 = STRICT (maximum filtering). | Default: 1 (MODERATE) |
Note: Safe search levels align with standard search API conventions. MODERATE filtering is enabled by default to provide reasonable content filtering while maintaining search effectiveness. Tavily does not inherit this global setting by default; use tavilySearchOptions.safeSearch only if your Tavily account supports safe_search.
Notes
- API keys can be configured in two ways:
- Set the environment variables specified in the YAML configuration
- If environment variables are not set, users will be prompted to provide the API keys via the UI
- The configuration supports multiple services for each component (providers, scrapers, rerankers)
- If a specific service type is not specified, the system will try all available services in that category
- Safe search provides three levels of content filtering: OFF (0), MODERATE (1), and STRICT (2)
- Tavily does not inherit the global safe search setting by default; set
tavilySearchOptions.safeSearchexplicitly only when your Tavily account supportssafe_search - Never put actual API keys in the YAML configuration - only use environment variable names
Setting Up SearXNG
SearXNG is a privacy-focused meta search engine that you can self-host. For more information, see the official SearXNG documentation.
Here are the steps to set up your own SearXNG instance for use with LibreChat:
Using Docker Desktop
-
Search for the official SearXNG image
- Open Docker Desktop
- Search for
searxng/searxngin the Images tab - Click Run on the official image to automatically pull down and run a container of the image
-
Running the container
- Expand the Optional Settings dropdown in the proceeding panel that appears once the download completes
- Set your desired configuration details (port number, container name, etc.)
- Click Run to start the container
-
Configure SearXNG for LibreChat
- Navigate to the
Filestab in Docker Desktop - Go to
/etc/searxng/settings.yaml - Open the file editor
- Navigate to the
formatssection - Add
jsonas an acceptable format so that LibreChat can communicate with your instance - Save the file
- Navigate to the
-
Restart the container
- Restart the container for the changes to take effect
Video Guide:
Here's a video to guide you through the process from start to finish in about a minute:
Note: In this example, the instance URL is http://localhost:55011 (port number found under the container name in the top left at the end of the video)
Configuring LibreChat to use SearXNG
You can configure SearXNG in LibreChat within the UI or through librechat.yaml.
UI Configuration
-
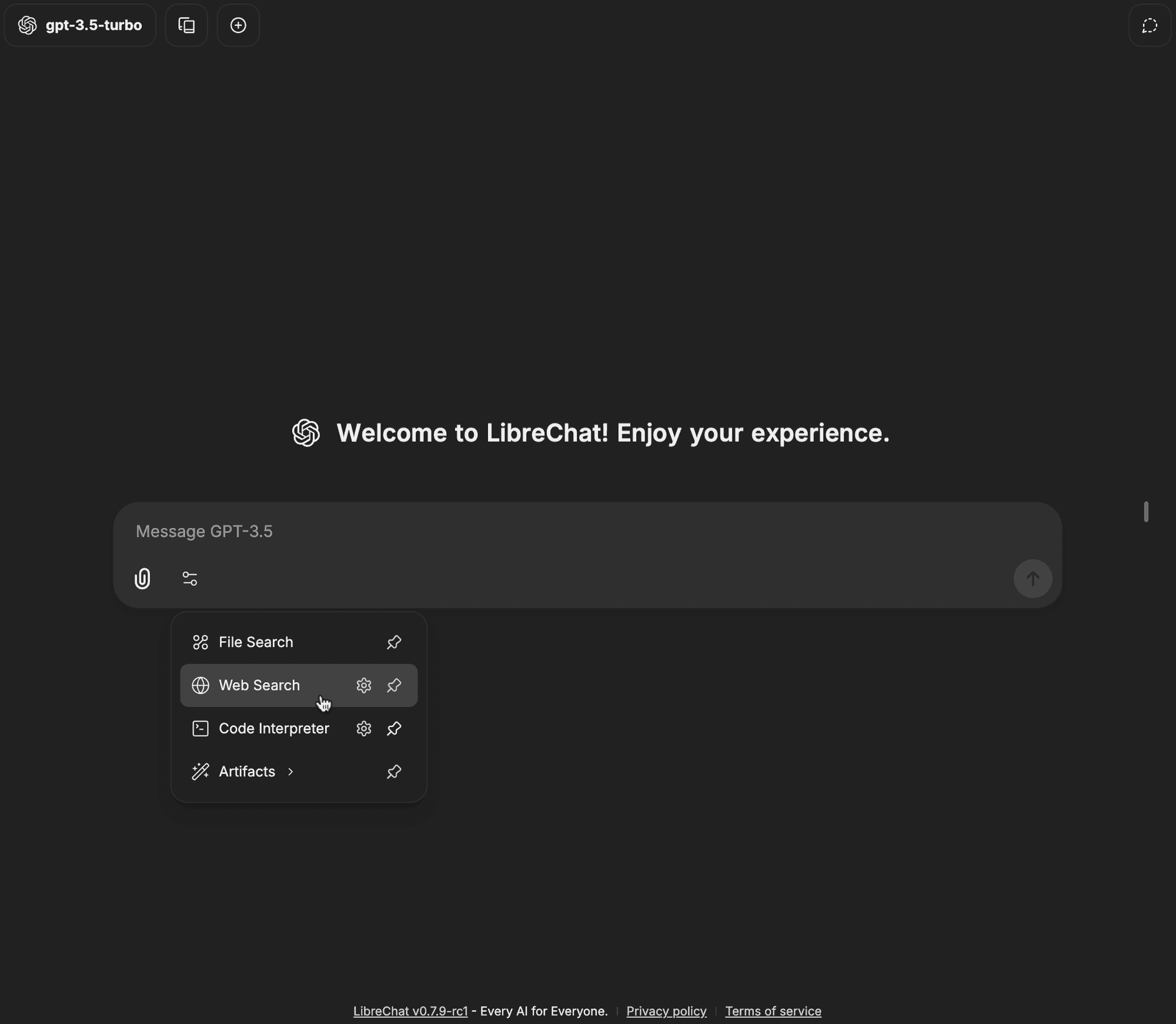
Open the tools dropdown in the chat input bar
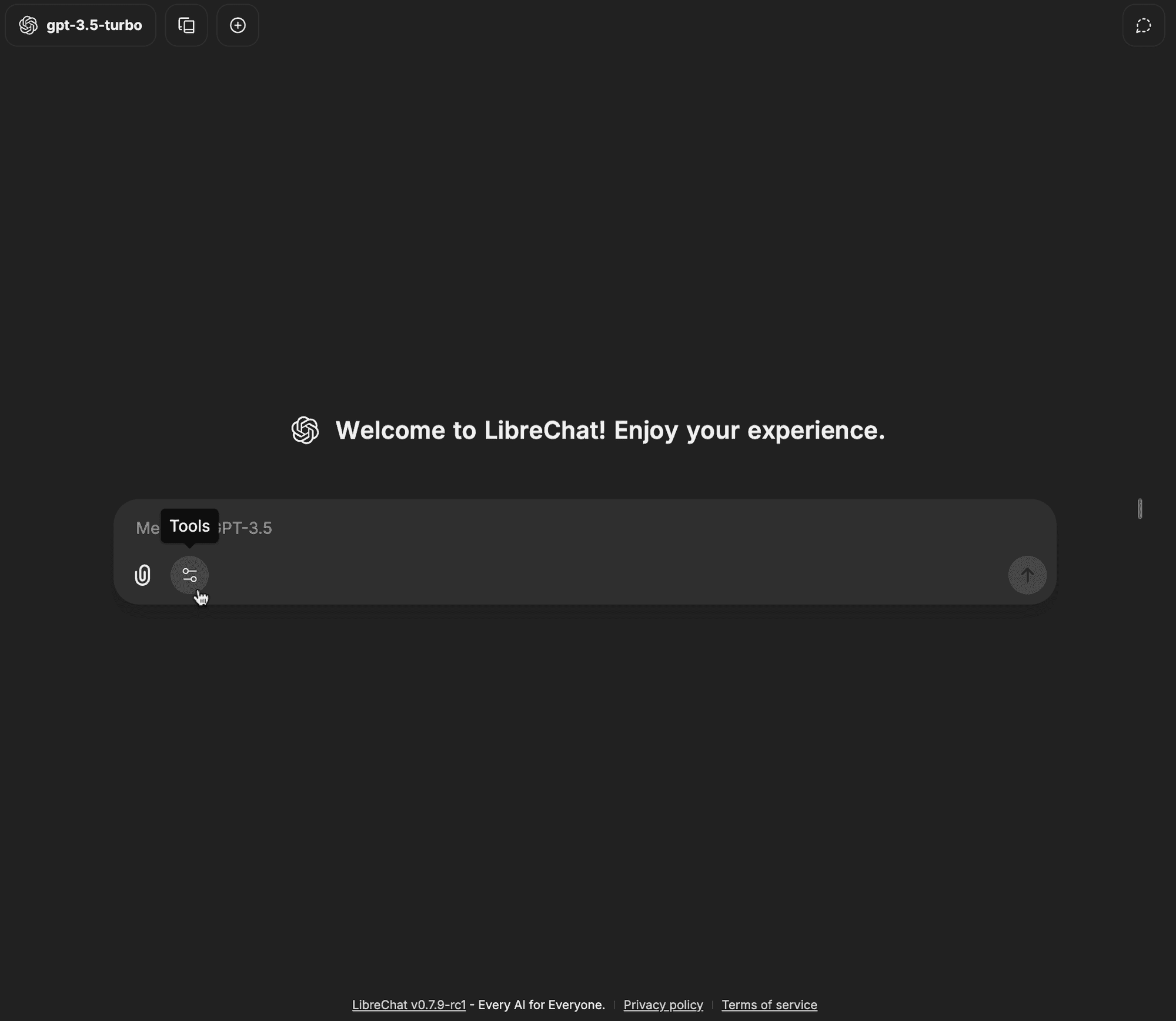
-
Click on the gear icon next to Web Search
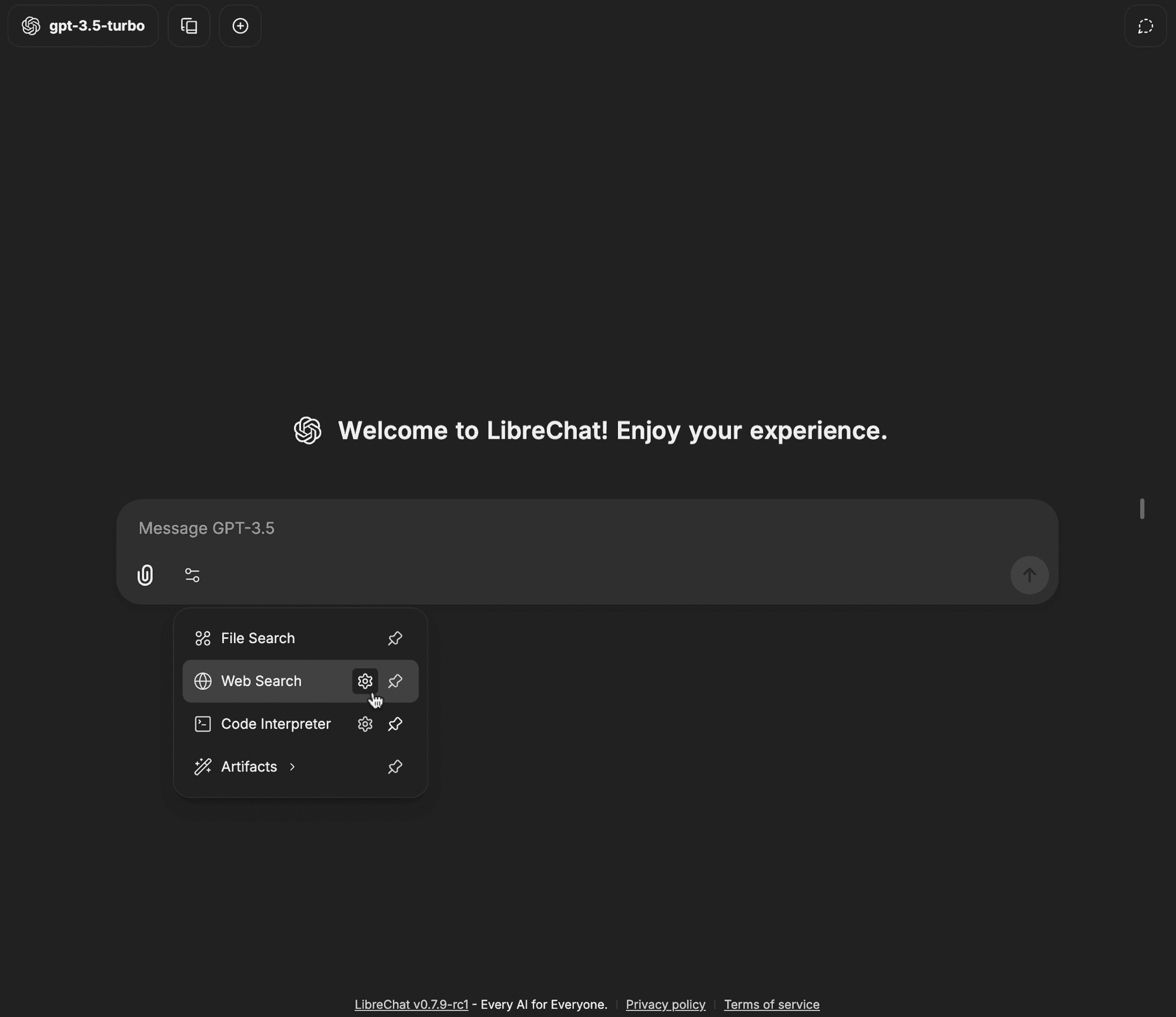
-
Select SearXNG from the Search Provider dropdown
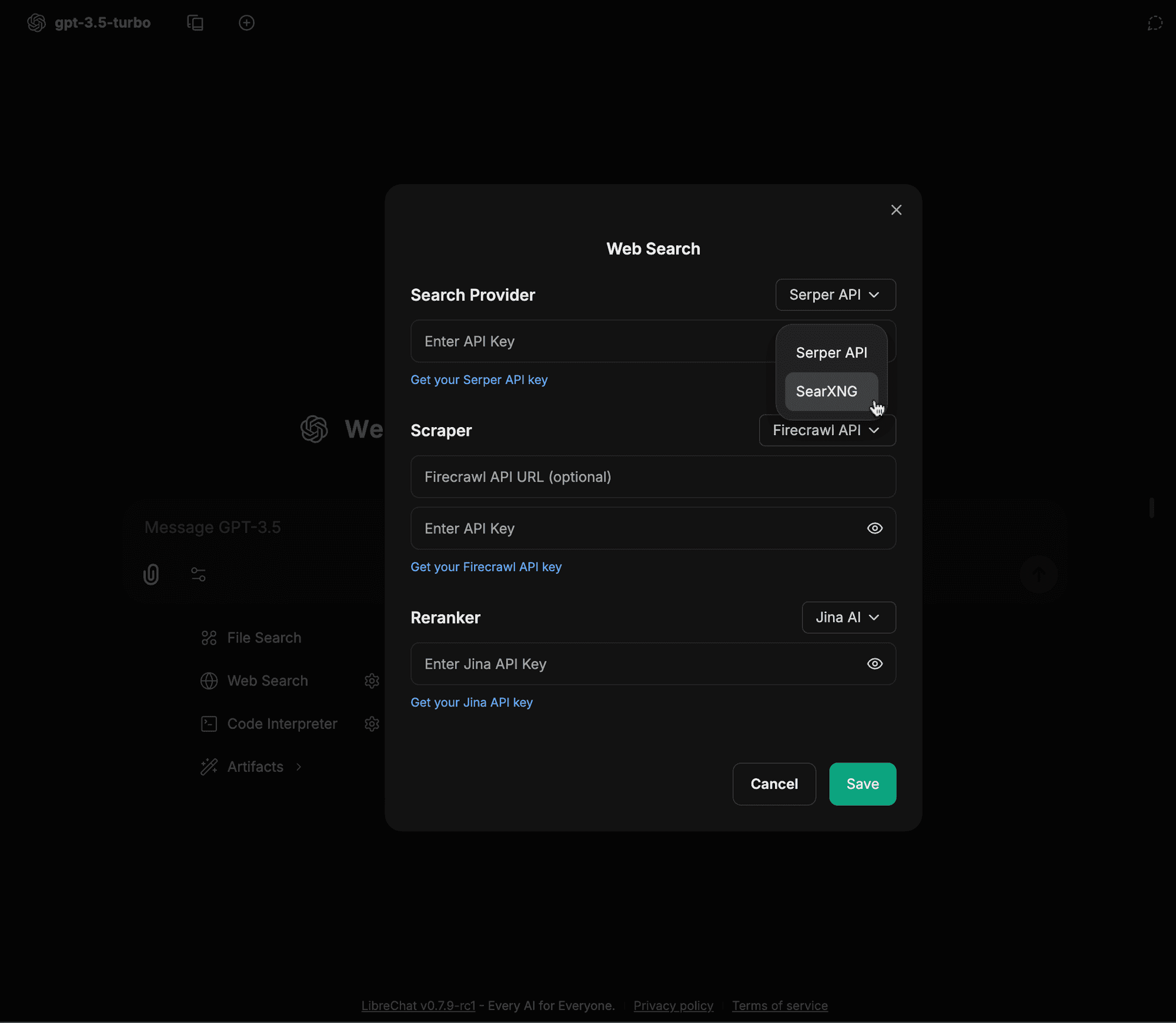
-
Enter your configuration details (e.g. instance URL, scraper type, etc.) and click save
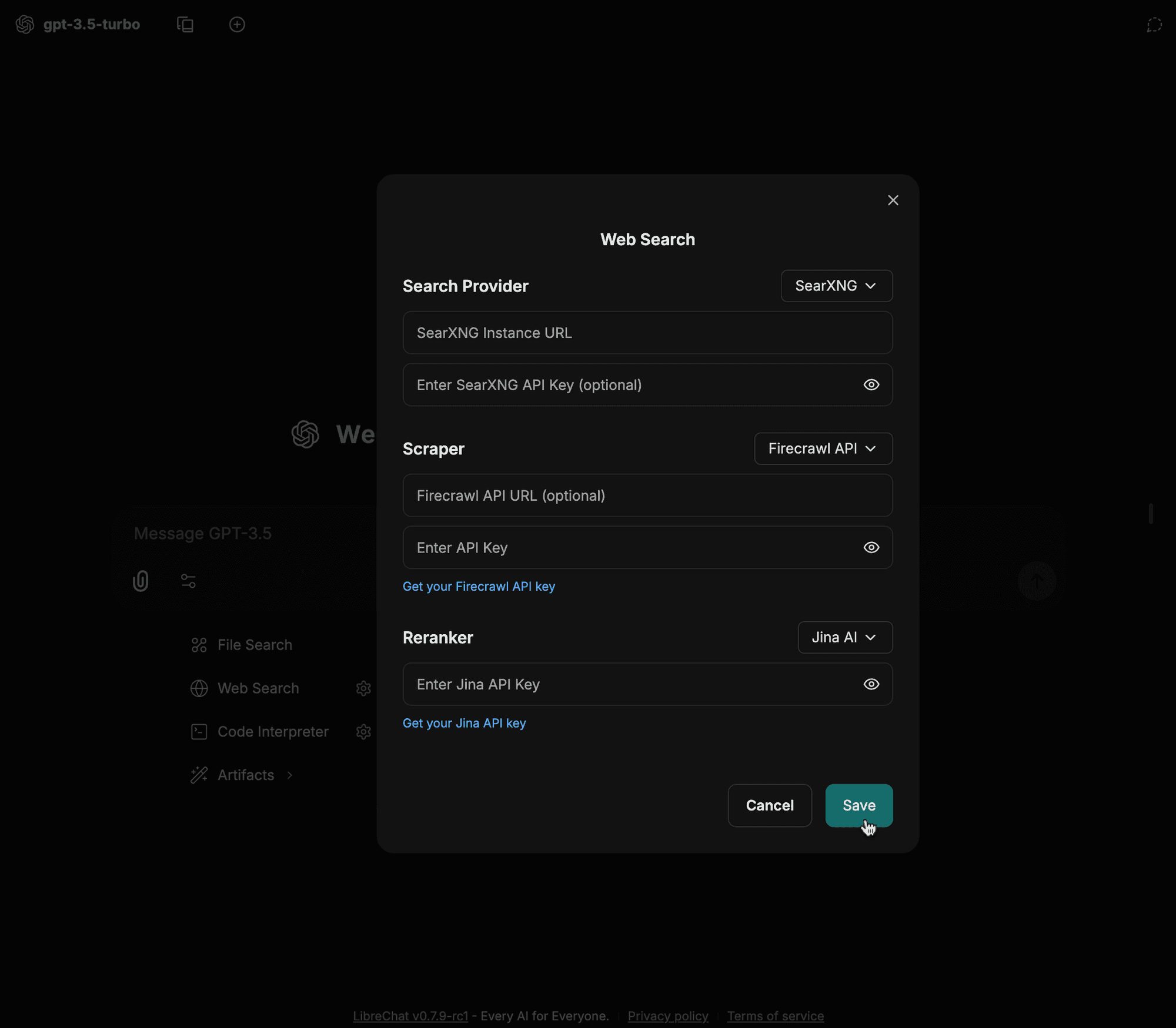
-
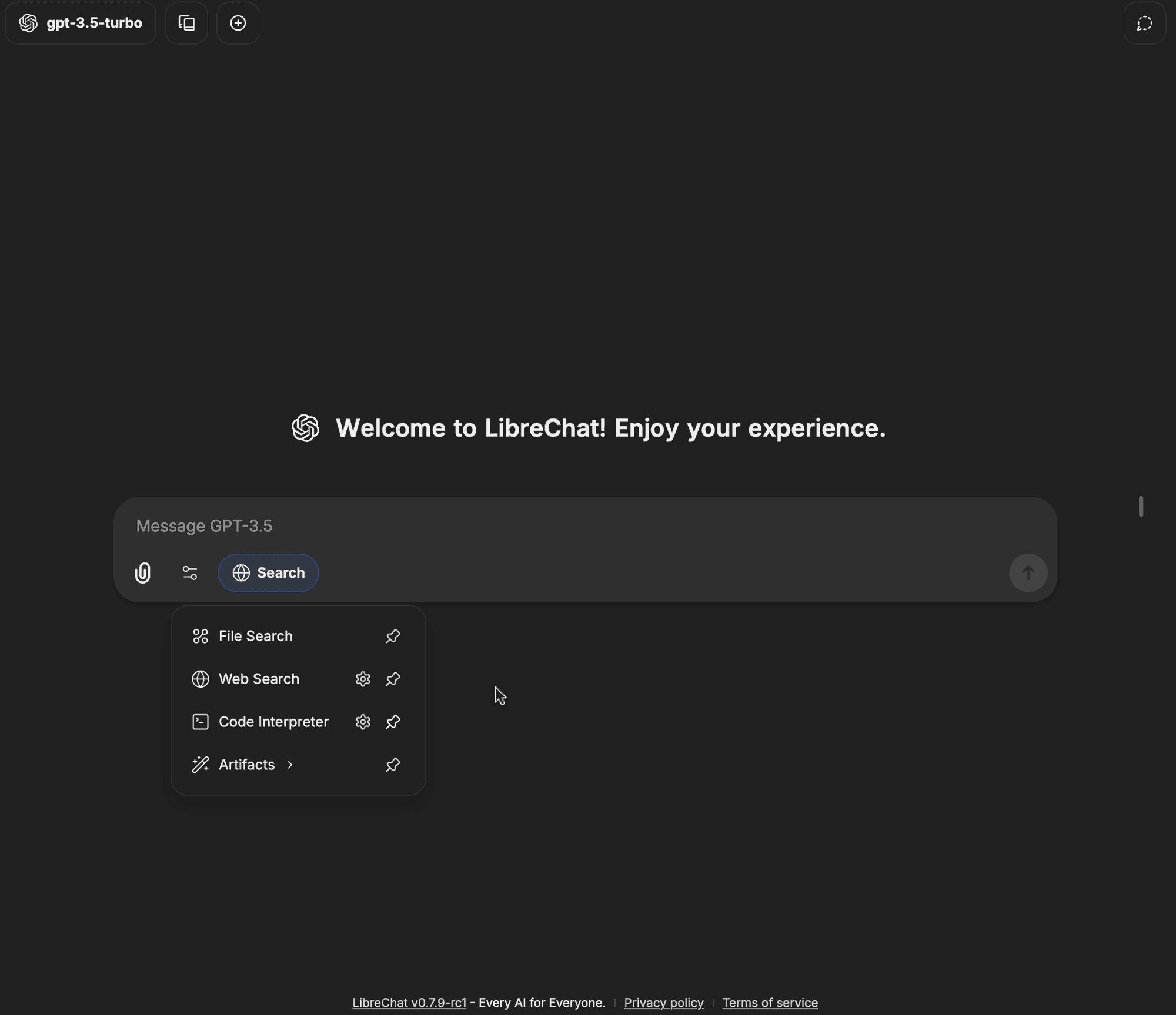
Click on the Web Search option in the tools dropdown
-
The Web Search badge should now be enabled, meaning your queries can now utilize the web search functionality
How is this guide?